1 Introduction
In previous publications I have covered regression models from the scikit-learn library and the statsmodel library. But besides these, there are a lot of other machine learning algorithms that can be used to create regression models. In this publication I would like to introduce them to you.
Short remark in advance: I will not go into the exact functioning of the different algorithms below. In the end I have provided a number of links to further publications of mine in which I explain the algorithms used in detail.
For this post the dataset House Sales in King County, USA from the statistic platform “Kaggle” was used. You can download it from my GitHub Repository.
The goal is to find an algorithm that can best predict house prices. The results of the algorithms will be stored in variables and presented in an overview at the end.
2 Loading the libraries and the data
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCV
from sklearn.linear_model import LinearRegression
from sklearn.tree import DecisionTreeRegressor
from sklearn.svm import SVR
from sklearn.linear_model import SGDRegressor
from sklearn.neighbors import KNeighborsRegressor
from sklearn.ensemble import BaggingRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.ensemble import AdaBoostRegressor
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.ensemble import StackingRegressor
from sklearn.linear_model import Lasso
from sklearn.linear_model import Ridgehouse = pd.read_csv("path/to/file/house_prices.csv")house = house.drop(['zipcode', 'lat', 'long', 'date', 'id'], axis=1)
house.head()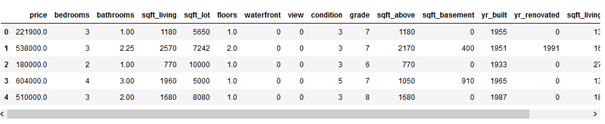
x = house.drop('price', axis=1)
y = house['price']
trainX, testX, trainY, testY = train_test_split(x, y, test_size = 0.2)3 Linear Regression
lm = LinearRegression()
lm.fit(trainX, trainY)
y_pred = lm.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 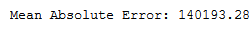
mae_lm = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_lm = lm.score(trainX, trainY)4 Decision Tree Regression
dt_reg = DecisionTreeRegressor()
dt_reg.fit(trainX, trainY)
y_pred = dt_reg.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 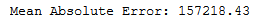
mae_dt_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_dt_reg = dt_reg.score(trainX, trainY)param_grid = {"criterion": ["mse", "mae"],
"min_samples_split": [10, 20, 40],
"max_depth": [2, 6, 8],
"min_samples_leaf": [20, 40, 100],
"max_leaf_nodes": [5, 20, 100],
}grid_dt_reg = GridSearchCV(dt_reg, param_grid, cv=5, n_jobs = -1) grid_dt_reg.fit(trainX, trainY)print(grid_dt_reg.best_params_)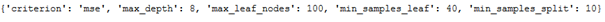
y_pred = grid_dt_reg.predict(testX)
print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2))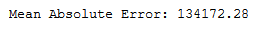
mae_grid_dt_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_grid_dt_reg = grid_dt_reg.score(trainX, trainY)5 Support Vector Machines Regression
svr = SVR(kernel='rbf')
svr.fit(trainX, trainY)
y_pred = svr.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 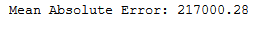
mae_svr = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_svr = svr.score(trainX, trainY)k = ['rbf']
c = [0.001, 0.10, 0.1, 10, 25, 50, 100, 1000]
g = [1, 0.1, 0.01, 0.001, 0.0001, 0.00001]
param_grid=dict(kernel=k, C=c, gamma=g)grid_svr = GridSearchCV(svr, param_grid, cv=5, n_jobs = -1)
grid_svr.fit(trainX, trainY)print(grid_svr.best_params_)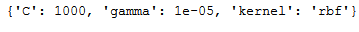
y_pred = grid_svr.predict(testX)
print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2))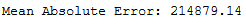
mae_grid_svr = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_grid_svr = grid_svr.score(trainX, trainY)6 Stochastic Gradient Descent (SGD) Regression
n_iters = list(range(1,10,1))
scores = []
for n_iter in n_iters:
sgd_reg = SGDRegressor(max_iter=n_iter)
sgd_reg.fit(trainX, trainY)
scores.append(sgd_reg.score(testX, testY))
plt.title("Effect of n_iter")
plt.xlabel("n_iter")
plt.ylabel("score")
plt.plot(n_iters, scores) 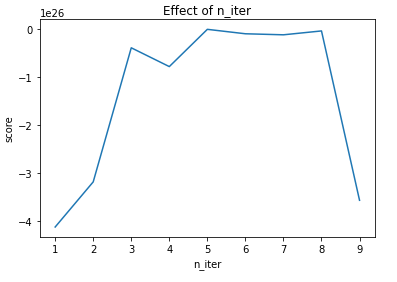
n_iter=5
sgd_reg = SGDRegressor(max_iter=n_iter)
sgd_reg.fit(trainX, trainY)
y_pred = sgd_reg.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 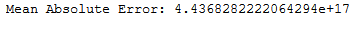
mae_sgd_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_sgd_reg = sgd_reg.score(trainX, trainY)params = {"alpha" : [0.0001, 0.001, 0.01, 0.1],
"penalty" : ["l2", "l1", "elasticnet", "none"],
}grid_sgd_reg = GridSearchCV(sgd_reg, param_grid=params, cv=5, n_jobs = -1)
grid_sgd_reg.fit(trainX, trainY)print(grid_sgd_reg.best_params_)
y_pred = grid_sgd_reg.predict(testX)
print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2))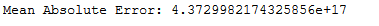
mae_grid_sgd_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_grid_sgd_reg = grid_sgd_reg.score(trainX, trainY)7 KNN Regression
k_range = range(1, 33)
scores = {}
scores_list = []
k_range = range(1, 33)
scores = {}
scores_list = []
for k in k_range:
knn_reg = KNeighborsRegressor(n_neighbors=k)
knn_reg.fit(trainX, trainY)
y_pred = knn_reg.predict(testX)
scores[k] = metrics.mean_absolute_error(testY, y_pred)
scores_list.append(metrics.mean_absolute_error(testY, y_pred))plt.plot(k_range, scores_list)
plt.xlabel('Value of K for KNN_reg')
plt.ylabel('MSE')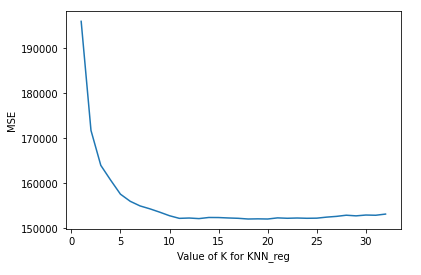
n_eighbors = 16
knn_reg = KNeighborsRegressor(n_neighbors=n_eighbors)
knn_reg.fit(trainX, trainY)
y_pred = knn_reg.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 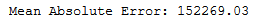
mae_knn_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_knn_reg = knn_reg.score(trainX, trainY)k_range = list(range(1,15))
weight_options = ["uniform", "distance"]
params = dict(n_neighbors=k_range, weights=weight_options)grid_knn_reg = GridSearchCV(knn_reg, param_grid=params, cv=5, n_jobs = -1)
grid_knn_reg.fit(trainX, trainY)print(grid_knn_reg.best_params_)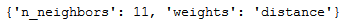
y_pred = grid_knn_reg.predict(testX)
print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2))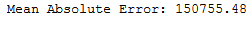
mae_grid_knn_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_grid_knn_reg = grid_knn_reg.score(trainX, trainY)8 Ensemble Modeling
I’ll define a function that returns the cross-validation RMSE error so we can evaluate our models and pick the best tuning part.
def rmse_cv(model):
rmse= np.sqrt(-cross_val_score(model, trainX, trainY, scoring="neg_mean_squared_error", cv = 5))
return(rmse)8.1 Bagging Regressor
n_estimators = [170, 200, 250, 300]
cv_rmse_br = [rmse_cv(BaggingRegressor(n_estimators = n_estimator)).mean()
for n_estimator in n_estimators]cv_br = pd.Series(cv_rmse_br , index = n_estimators)
cv_br.plot(title = "Validation BaggingRegressor")
plt.xlabel("n_estimator")
plt.ylabel("rmse")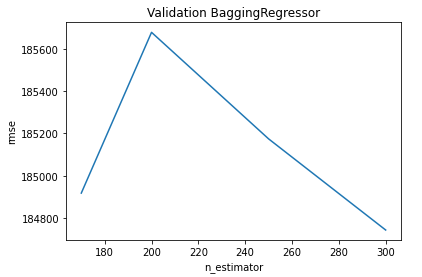
cv_br.min()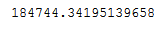
n_estimators = 300
bagging_reg = BaggingRegressor(n_estimators = n_estimators)
bagging_reg.fit(trainX, trainY)
y_pred = bagging_reg.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 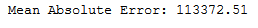
mae_bagging_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_bagging_reg = bagging_reg.score(trainX, trainY)8.2 Bagging Regressor with Decision Tree Reg as base_estimator
As the base estimator I’ll use a DecisionTreeRegressor with the best parameters calculated with grid search under chapter 4.
dt_reg_with_grid_params = DecisionTreeRegressor(criterion = 'mse', max_depth= 8, max_leaf_nodes= 100, min_samples_leaf= 20, min_samples_split= 10) n_estimators = 250
bc_params = {
'base_estimator': dt_reg_with_grid_params,
'n_estimators': n_estimators
}bagging_reg_plus_dtr = BaggingRegressor(**bc_params)
bagging_reg_plus_dtr.fit(trainX, trainY)
y_pred = bagging_reg_plus_dtr.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 
mae_bagging_reg_plus_dtr = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_bagging_reg_plus_dtr = bagging_reg_plus_dtr.score(trainX, trainY)8.3 Random Forest Regressor
n_estimators = 250
rf_reg = RandomForestRegressor(n_estimators = n_estimators)
rf_reg.fit(trainX, trainY)
y_pred = rf_reg.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 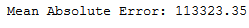
mae_rf_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_rf_reg = rf_reg.score(trainX, trainY)param_dist = {"max_depth": list(range(3,20)),
"max_features": list(range(1, 10)),
"min_samples_split": list(range(2, 11)),
"bootstrap": [True, False],
"criterion": ["mse", "mae"]}n_iter_search = 10
rs_rf_reg = RandomizedSearchCV(rf_reg, param_distributions=param_dist,
n_iter=n_iter_search, n_jobs = -1)
rs_rf_reg.fit(trainX, trainY)print(rs_rf_reg.best_params_)
y_pred = rs_rf_reg.predict(testX)
print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2))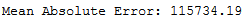
mae_rs_rf_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_rs_rf_reg = rs_rf_reg.score(trainX, trainY)8.4 AdaBoost Regressor
n_estimators = [170, 200, 250, 300]
cv_rmse_ab_reg = [rmse_cv(AdaBoostRegressor(n_estimators = n_estimator)).mean()
for n_estimator in n_estimators]cv_ab_reg = pd.Series(cv_rmse_ab_reg , index = n_estimators)
cv_ab_reg.plot(title = "Validation AdaBoost Regressor")
plt.xlabel("n_estimator")
plt.ylabel("rmse")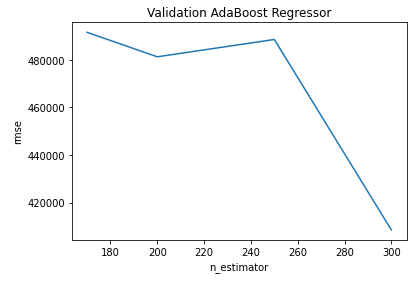
cv_ab_reg.min()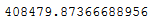
n_estimators = 300
ab_reg = AdaBoostRegressor(n_estimators = n_estimators)
ab_reg.fit(trainX, trainY)
y_pred = ab_reg.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 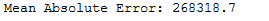
mae_ab_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_ab_reg = ab_reg.score(trainX, trainY)8.5 AdaBoost Regressor with Decision Tree Reg as base_estimator
I will use again the DecisionTreeRegressor with the best parameters calculated with grid search under chapter 4.
dt_reg_with_grid_params = DecisionTreeRegressor(criterion = 'mse', max_depth= 8, max_leaf_nodes= 100, min_samples_leaf= 20, min_samples_split= 10) n_estimators = 300
ab_params = {
'n_estimators': n_estimators,
'base_estimator': dt_reg_with_grid_params
}ab_reg_plus_dtr = AdaBoostRegressor(**ab_params)
ab_reg_plus_dtr.fit(trainX, trainY)
y_pred = ab_reg_plus_dtr.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 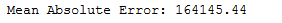
mae_ab_reg_plus_dtr = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_ab_reg_plus_dtr = ab_reg_plus_dtr.score(trainX, trainY)8.6 Gradient Boosting Regressor
n_estimators = [150, 170 , 200, 400, 500]
cv_rmse_gb_reg = [rmse_cv(GradientBoostingRegressor(n_estimators = n_estimator)).mean()
for n_estimator in n_estimators]cv_gb_reg = pd.Series(cv_rmse_gb_reg , index = n_estimators)
cv_gb_reg.plot(title = "Validation Gradient Boosting Regressor")
plt.xlabel("n_estimator")
plt.ylabel("rmse")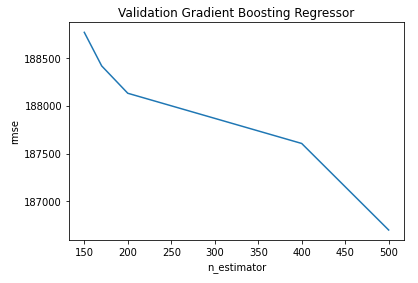
cv_gb_reg.min()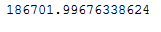
n_estimators = 500
gb_reg = GradientBoostingRegressor(n_estimators = n_estimators)
gb_reg.fit(trainX, trainY)
y_pred = gb_reg.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 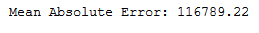
mae_gb_reg = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_gb_reg = gb_reg.score(trainX, trainY)8.7 Stacking Regressor
ridge = Ridge()
lasso = Lasso()estimators = [
('ridge', Ridge()),
('lasso', Lasso())]sr = StackingRegressor(estimators=estimators, final_estimator=LinearRegression())
sr.fit(trainX, trainY)
y_pred = sr.predict(testX)print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2)) 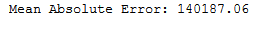
mae_sr = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_sr = sr.score(trainX, trainY)params = {'lasso__alpha': [x*5.0 for x in range(1, 10)],
'ridge__alpha': [x/5.0 for x in range(1, 10)]}grid_sr = GridSearchCV(sr, param_grid=params, cv=5)
grid_sr.fit(trainX, trainY)print(grid_sr.best_params_)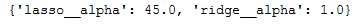
y_pred = grid_sr.predict(testX)
print('Mean Absolute Error:', round(metrics.mean_absolute_error(testY, y_pred), 2))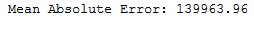
mae_grid_sr = round(metrics.mean_absolute_error(testY, y_pred), 2)
r_grid_sr = grid_sr.score(trainX, trainY)9 Overview Results
Now it is time to collect the calculated results.
column_names = ["Algorithmus", "MAE", "R²"]
df = pd.DataFrame(columns = column_names)
lm_df = pd.DataFrame([('lm', mae_lm, r_lm)], columns=column_names)
df = df.append(lm_df)
dt_reg_df = pd.DataFrame([('dt_reg', mae_dt_reg, r_dt_reg)], columns=column_names)
df = df.append(dt_reg_df)
grid_dt_reg_df = pd.DataFrame([('grid_dt_reg', mae_grid_dt_reg, r_grid_dt_reg)], columns=column_names)
df = df.append(grid_dt_reg_df)
svr_df = pd.DataFrame([('svr', mae_svr, r_svr)], columns=column_names)
df = df.append(svr_df)
grid_svr_df = pd.DataFrame([('grid_svr', mae_grid_svr, r_grid_svr)], columns=column_names)
df = df.append(grid_svr_df)
sgd_reg_df = pd.DataFrame([('sgd_reg', mae_sgd_reg, r_sgd_reg)], columns=column_names)
df = df.append(sgd_reg_df)
grid_sgd_reg_df = pd.DataFrame([('grid_sgd_reg', mae_grid_sgd_reg, r_grid_sgd_reg)], columns=column_names)
df = df.append(grid_sgd_reg_df)
knn_reg_df = pd.DataFrame([('knn_reg', mae_knn_reg, r_knn_reg)], columns=column_names)
df = df.append(knn_reg_df)
grid_knn_reg_df = pd.DataFrame([('grid_knn_reg', mae_grid_knn_reg, r_grid_knn_reg)], columns=column_names)
df = df.append(grid_knn_reg_df)
bagging_reg_df = pd.DataFrame([('bagging_reg', mae_bagging_reg, r_bagging_reg)], columns=column_names)
df = df.append(bagging_reg_df)
bagging_reg_plus_dtr_df = pd.DataFrame([('bagging_reg_plus_dtr', mae_bagging_reg_plus_dtr, r_bagging_reg_plus_dtr)], columns=column_names)
df = df.append(bagging_reg_plus_dtr_df)
rf_reg_df = pd.DataFrame([('rf_reg', mae_rf_reg, r_rf_reg)], columns=column_names)
df = df.append(rf_reg_df)
rs_rf_reg_df = pd.DataFrame([('rs_rf_reg', mae_rs_rf_reg, r_rs_rf_reg)], columns=column_names)
df = df.append(rs_rf_reg_df)
ab_reg_df = pd.DataFrame([('ab_reg', mae_ab_reg, r_ab_reg)], columns=column_names)
df = df.append(ab_reg_df)
ab_reg_plus_dtr_df = pd.DataFrame([('ab_reg_plus_dtr', mae_ab_reg_plus_dtr, r_ab_reg_plus_dtr)], columns=column_names)
df = df.append(ab_reg_plus_dtr_df)
gb_reg_df = pd.DataFrame([('gb_reg', mae_gb_reg, r_gb_reg)], columns=column_names)
df = df.append(gb_reg_df)
sr_df = pd.DataFrame([('sr', mae_sr, r_sr)], columns=column_names)
df = df.append(sr_df)
grid_sr_df = pd.DataFrame([('grid_sr', mae_grid_sr, r_grid_sr)], columns=column_names)
df = df.append(grid_sr_df)
df['MAE'] = np.round(df['MAE'], decimals=3)
df['R²'] = np.round(df['R²'], decimals=3)
df = df.rename(columns={'R²': 'R'})
df['R²'] = abs(df.R)
df = df.drop(columns=['R'])
df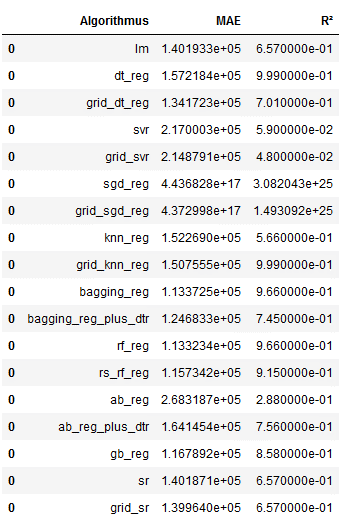
Ok this overview is not really readable yet. We can do better:
pd.options.display.float_format = '{:.5f}'.format
df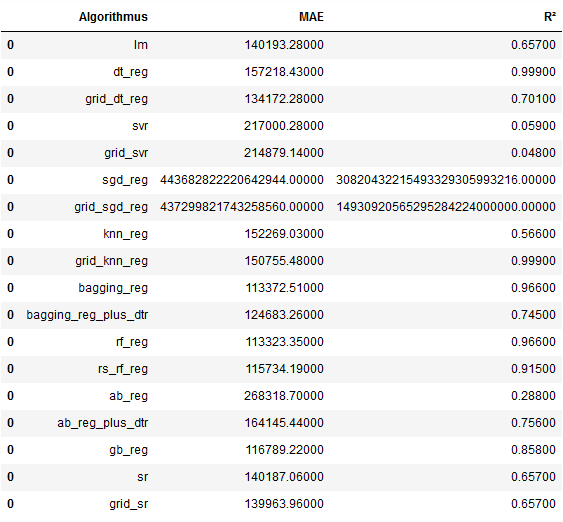
Now we display the MAE values in ascending order.
best_MAE = df.sort_values(by='MAE', ascending=True)
best_MAE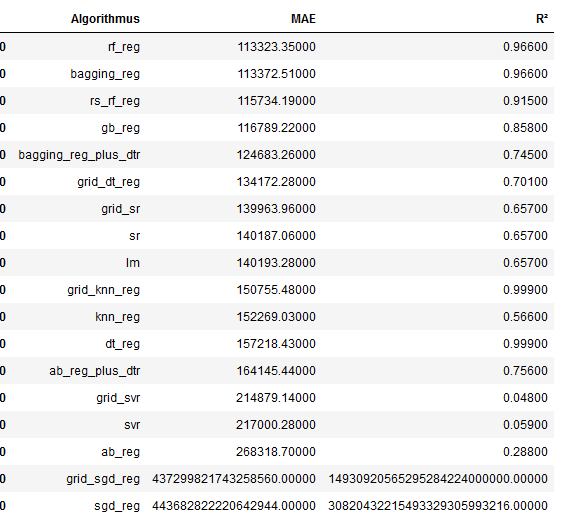
From the overview we can see that the RandomForestRegressor is the algorithm that achieved the best results.
pd.reset_option('display.float_format')What these metrics mean and how to interpret them I have described in the following post: Metrics for Regression Analysis
10 Conclusion
In this post I have shown which different machine learning algorithms are available to create regression models. The explanation of the exact functionality of the individual algorithms was not central. But I did explain them when I used these algorithms for classification problems. Have a look here: