1 Introduction
After “Bagging” we come to another type of ensemble method: Boosting.
For this post the dataset Bank Data from the platform “UCI Machine Learning Repository” was used. You can download it from my “GitHub Repository”.
2 Background Information on Boosting
Boosting often considers homogeneous weak learners and learns them sequentially in a very adaptative way (a base model depends on the previous ones) and combines them following a deterministic strategy.
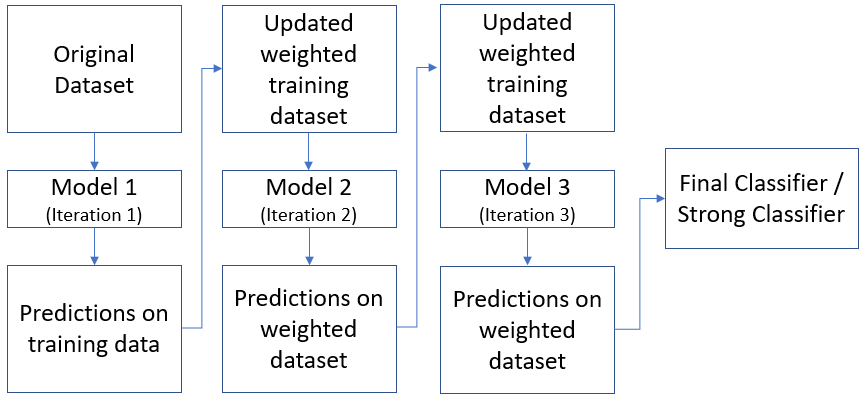
To get a better understanding of the difference between Bagging and Boosting read this “article”
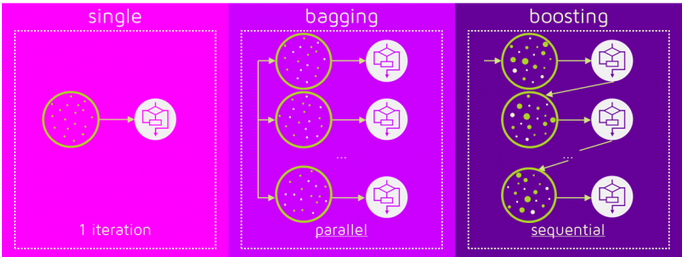
Source: “QuantDare”
3 Loading the libraries and the data
import numpy as np
import pandas as pd
%matplotlib inline
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
from sklearn.ensemble import GradientBoostingClassifierbank = pd.read_csv("path/to/file/bank.csv", sep=";")
bank.head()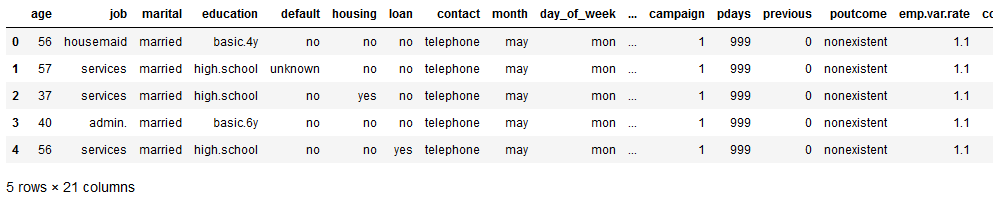
The data set before us contains information about whether a customer has signed a contract or not.
bank['y'].value_counts().T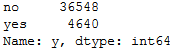
4 Data pre-processing
We do exactly the same data pre-processing steps like in the previous post about “Bagging”.
safe_y = bank[['y']]
col_to_exclude = ['y']
bank = bank.drop(col_to_exclude, axis=1)#Just select the categorical variables
cat_col = ['object']
cat_columns = list(bank.select_dtypes(include=cat_col).columns)
cat_data = bank[cat_columns]
cat_vars = cat_data.columns
#Create dummy variables for each cat. variable
for var in cat_vars:
cat_list = pd.get_dummies(bank[var], prefix=var)
bank=bank.join(cat_list)
data_vars=bank.columns.values.tolist()
to_keep=[i for i in data_vars if i not in cat_vars]
#Create final dataframe
bank_final=bank[to_keep]
bank_final.columns.values
bank = pd.concat([bank_final, safe_y], axis=1)
bank
Now let’s split the dataframe for further processing.
x = bank.drop('y', axis=1)
y = bank['y']
trainX, testX, trainY, testY = train_test_split(x, y, test_size = 0.2)5 AdaBoost (Adaptive Boosting)
AdaBoost or Adaptive Boosting is one of ensemble boosting classifier proposed by Yoav Freund and Robert Schapire. It combines multiple classifiers to increase the accuracy of classifiers. AdaBoost is an iterative ensemble method. AdaBoost classifier builds a strong classifier by combining multiple poorly performing classifiers so that you will get high accuracy strong classifier. The basic concept behind Adaboost is to set the weights of classifiers and training the data sample in each iteration such that it ensures the accurate predictions of unusual observations. Any machine learning algorithm can be used as base classifier if it accepts weights on the training set. Adaboost should meet two conditions:
- The classifier should be trained interactively on various weighed training examples.
- In each iteration, it tries to provide an excellent fit for these examples by minimizing training error.
Now let’s implement an AdaBoost-Classifier with a decision tree classifier as a base estimator:
dt_params = {
'max_depth': 1,
'random_state': 11
}
dt = DecisionTreeClassifier(**dt_params)ab_params = {
'n_estimators': 100,
'base_estimator': dt,
'random_state': 11
}
ab = AdaBoostClassifier(**ab_params)ab.fit(trainX, trainY)
ab_preds_train = ab.predict(trainX)
ab_preds_test = ab.predict(testX)print('Adaptive Boosting:\n> Accuracy on training data = {:.4f}\n> Accuracy on validation data = {:.4f}'.format(
accuracy_score(y_true=trainY, y_pred=ab_preds_train),
accuracy_score(y_true=testY, y_pred=ab_preds_test)
))
Now let’s see how the accuracy change with the number of estimators:
ab_params = {
'base_estimator': dt,
'random_state': 11
}
n_estimator_values = list(range(10, 360, 10))
train_accuracies, test_accuracies = [], []
for n_estimators in n_estimator_values:
ab = AdaBoostClassifier(n_estimators=n_estimators, **ab_params)
ab.fit(trainX, trainY)
ab_preds_train = ab.predict(trainX)
ab_preds_test = ab.predict(testX)
train_accuracies.append(accuracy_score(y_true=trainY, y_pred=ab_preds_train))
test_accuracies.append(accuracy_score(y_true=testY, y_pred=ab_preds_test))plt.figure(figsize=(10,7))
plt.plot(n_estimator_values, train_accuracies, label='Train')
plt.plot(n_estimator_values, test_accuracies, label='Validation')
plt.ylabel('Accuracy score')
plt.xlabel('n_estimators')
plt.legend()
plt.show()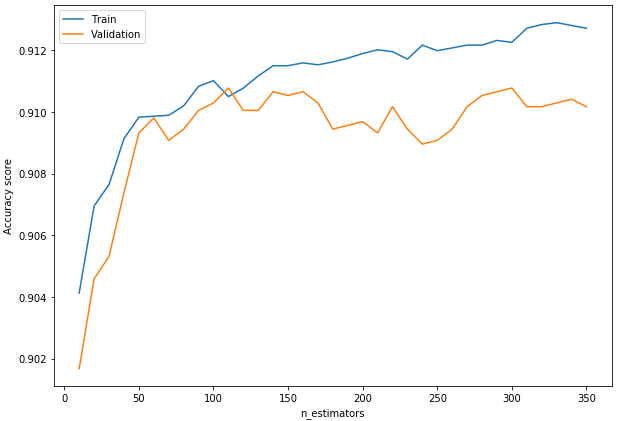
6 Gradient Boosting
It is also called Gradient Tree Boost classifier and is an extension to the boosting method that visualizes boosting as an optimization problem. Here we also combine many weak learning models together to create a strong predictive model. Gradient boosting models are becoming popular because of their effectiveness at classifying complex datasets.
gbc_params = {
'n_estimators': 100,
'max_depth': 3,
'min_samples_leaf': 5,
'random_state': 11
}
gbc = GradientBoostingClassifier(**gbc_params)gbc.fit(trainX, trainY)
gbc_preds_train = gbc.predict(trainX)
gbc_preds_test = gbc.predict(testX)print('Gradient Boosting Classifier:\n> Accuracy on training data = {:.4f}\n> Accuracy on validation data = {:.4f}'.format(
accuracy_score(y_true=trainY, y_pred=gbc_preds_train),
accuracy_score(y_true=testY, y_pred=gbc_preds_test)
))
7 Conclusion
In this second post on ensemble methods, I presented the method of Boosting. In this publication I showed what boosting is, how it should be differentiated from bagging and how it can be used for classification problems.
References
The content of the entire post was created using the following sources:
Johnston, B. & Mathur, I (2019). Applied Supervised Learning with Python. UK: Packt