1 Introduction
I have already presented three different Ensemble Methods “Bagging”, “Boosting” and “Stacking”. But there is another one that I would like to report on in this publication: Voting
Voting is an ensemble machine learning model that combines the predictions from multiple other models. It is a technique that may be used to improve model performance, ideally achieving better performance than any single model used in the ensemble. A voting ensemble works by combining the predictions from multiple models. It can be used for classification or regression. In the case of regression, this involves calculating the average of the predictions from the models. In the case of classification, the predictions for each label are summed and the label with the majority vote is predicted.
For this post the dataset Bank Data from the platform “UCI Machine Learning Repository” was used. You can download it from my “GitHub Repository”.
2 Background Information on Voting
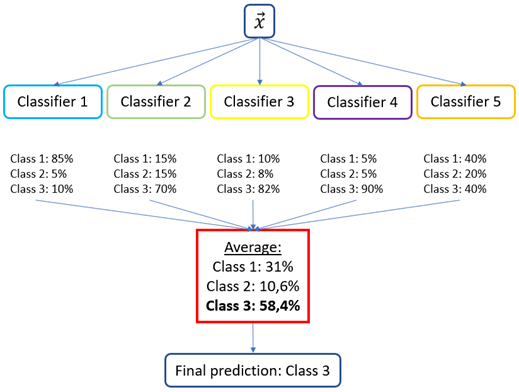
A voting classifier works like an electoral system in which a predictions on new data points is made based on a voting system of the members of a group of machine learning models. According to the documentation of scikit-learn, one may choose between the hard and the soft voting type.
The hard voting is applied to predicted class labels for majority rule voting. This uses the idea of “Majority carries the vote” i.e. a decision is made in favor of whoever has more than half of the vote.
The soft voting type, predicts the class label based on the argmax of the sums of the predicted probabilities of the individual estimators that make up the ensemble. The soft voting is often recommended in the case of an ensemble of well-calibrated/fitted classifiers.
Differentiation from stacking
Stacking involves combining the predictions from multiple machine learning models on the same set of data. We first specify/build some machine learning models called base estimators on our dataset, the results from these base learners then serve as input into our Stacking Classifier. The Stacking Classifier is able to learn when our base estimators can be trusted or not. Stacking allows us to use the strength of each individual estimator by using their output as an input of a final estimator.
In a nutshell:
The fundamental difference between voting and stacking is how the final aggregation is done. In voting, user-specified weights are used to combine the classifiers whereas stacking performs this aggregation by using a blender/meta classifier.
3 Loading the libraries and the data
import numpy as np
import pandas as pd
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import VotingClassifier
import warnings
warnings.filterwarnings("ignore")bank = pd.read_csv("path/to/file/bank.csv", sep=";")4 Data pre-processing
Since I use the same data approach as with “Stacking”, I will not go into the pre-processing steps individually below. If you want to know what is behind the individual pre-processing steps, read “this” post.
safe_y = bank[['y']]
col_to_exclude = ['y']
bank = bank.drop(col_to_exclude, axis=1)#Just select the categorical variables
cat_col = ['object']
cat_columns = list(bank.select_dtypes(include=cat_col).columns)
cat_data = bank[cat_columns]
cat_vars = cat_data.columns
#Create dummy variables for each cat. variable
for var in cat_vars:
cat_list = pd.get_dummies(bank[var], prefix=var)
bank=bank.join(cat_list)
data_vars=bank.columns.values.tolist()
to_keep=[i for i in data_vars if i not in cat_vars]
#Create final dataframe
bank_final=bank[to_keep]
bank_final.columns.valuesbank = pd.concat([bank_final, safe_y], axis=1)encoder = LabelBinarizer()
encoded_y = encoder.fit_transform(bank.y.values.reshape(-1,1))bank['y_encoded'] = encoded_y
bank['y_encoded'] = bank['y_encoded'].astype('int64')x = bank.drop(['y', 'y_encoded'], axis=1)
y = bank['y_encoded']
trainX, testX, trainY, testY = train_test_split(x, y, test_size = 0.2)5 Voting with scikit learn
We use the 4 algorithms below as estimators for scikit learn’s voting classifier.
knn = KNeighborsClassifier()
gnb = GaussianNB()
rf = RandomForestClassifier()
lr = LogisticRegression()classifiers = [('knn', knn),
('gnb', gnb),
('rf', rf),
('lr', lr)]vc = VotingClassifier(estimators=classifiers, voting='hard')Let’s calculate the cross_val_score for all of the estimators as well as the Voting Classifier:
print('knn cross_val_score:' + str(cross_val_score(knn, trainX, trainY, scoring='accuracy', cv=10).mean()))
print('gnb cross_val_score:' + str(cross_val_score(gnb, trainX, trainY, scoring='accuracy', cv=10).mean()))
print('rf cross_val_score:' + str(cross_val_score(rf, trainX, trainY, scoring='accuracy', cv=10).mean()))
print('lr cross_val_score:' + str(cross_val_score(lr, trainX, trainY, scoring='accuracy', cv=10).mean()))
print('vc cross_val_score:' + str(cross_val_score(vc, trainX, trainY, scoring='accuracy', cv=10).mean()))
Now we put this information in a clearer format:
a = []
a.append(cross_val_score(knn, trainX, trainY, scoring='accuracy', cv=10).mean())
a.append(cross_val_score(gnb, trainX, trainY, scoring='accuracy', cv=10).mean())
a.append(cross_val_score(rf, trainX, trainY, scoring='accuracy', cv=10).mean())
a.append(cross_val_score(lr, trainX, trainY, scoring='accuracy', cv=10).mean())
a.append(cross_val_score(vc, trainX, trainY, scoring='accuracy', cv=10).mean())
a = pd.DataFrame(a, columns=['cross_val_score'])
a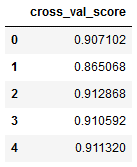
classifier = pd.DataFrame(classifiers, columns=['classifier', 'Parameter'])
voting_clf = [('vc', vc)]
voting_clf = pd.DataFrame(voting_clf, columns=['classifier', 'Parameter'])
classifier = classifier.append(voting_clf)
classifier = classifier['classifier']
classifier = pd.DataFrame(classifier)
classifier
classifier = pd.DataFrame(classifiers, columns=['classifier', 'Parameter'])
voting_clf = [('vc', vc)]
voting_clf = pd.DataFrame(voting_clf, columns=['classifier', 'Parameter'])
classifier = classifier.append(voting_clf)
classifier = classifier['classifier']
classifier.reset_index(drop=True, inplace=True)
a.reset_index(drop=True, inplace=True)
overview_results = pd.concat([classifier, a], axis=1)
overview_results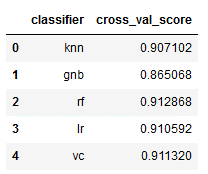
Okay. Now we put the achieved scores in a descending order:
overview_results.sort_values(by='cross_val_score', ascending=False)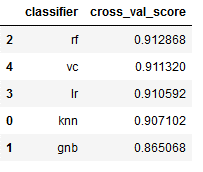
As we can see, the Random Forest Classifier achieved the best scores. Let’s see if we can get a better performance with Grid-Search.
6 GridSearch
With Grid Search we search for two different parameters:
- Voting type
- Weights
With Voting Types there are only two possible selection criteria. The number of different weight settings depends on the number of estimators used. Here we used 4 plus the VotingClassifier itself.
# define VotingClassifier parameters to search
params = {'voting':['hard', 'soft'],
'weights':[(1,1,1,1), (2,1,1,1), (1,2,1,1), (1,1,2,1), (1,1,1,2)]}# find the best set of parameters
grid = GridSearchCV(estimator=vc, param_grid=params, cv=5, scoring='accuracy')
grid.fit(trainX, trainY)The calculated best parameter settings are as follows:
print(grid.best_params_) 
Now let’s calculate the cross_val_score for this parameter setting:
print('vc cross_val_score with GridSearch:' + str(cross_val_score(grid, trainX, trainY, scoring='accuracy', cv=10).mean()))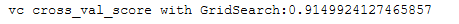
For a uniform view, we transfer the calculated values to the previously created overview.
overview_results = overview_results.append({'classifier' : 'vc_plus_gridsearch' , 'cross_val_score' : 0.9149924127465857} , ignore_index=True)
overview_results.sort_values(by='cross_val_score', ascending=False)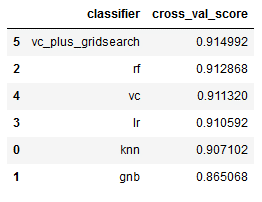
Perfect, we have managed to increase the performance again. Now the values are higher than those at Random Forest.
7 Overview of the accuracy scores
Finally, I would like to give an overview of the accuracy scores achieved for the individual models.
knn.fit(trainX, trainY)
clf_preds_train = knn.predict(trainX)
clf_preds_test = knn.predict(testX)
print('knn Classifier:\n> Accuracy on training data = {:.4f}\n> Accuracy on test data = {:.4f}'.format(
accuracy_score(y_true=trainY, y_pred=clf_preds_train),
accuracy_score(y_true=testY, y_pred=clf_preds_test)
))
gnb.fit(trainX, trainY)
clf_preds_train = gnb.predict(trainX)
clf_preds_test = gnb.predict(testX)
print('gnb Classifier:\n> Accuracy on training data = {:.4f}\n> Accuracy on test data = {:.4f}'.format(
accuracy_score(y_true=trainY, y_pred=clf_preds_train),
accuracy_score(y_true=testY, y_pred=clf_preds_test)
))
rf.fit(trainX, trainY)
clf_preds_train = rf.predict(trainX)
clf_preds_test = rf.predict(testX)
print('rf Classifier:\n> Accuracy on training data = {:.4f}\n> Accuracy on test data = {:.4f}'.format(
accuracy_score(y_true=trainY, y_pred=clf_preds_train),
accuracy_score(y_true=testY, y_pred=clf_preds_test)
))
lr.fit(trainX, trainY)
clf_preds_train = lr.predict(trainX)
clf_preds_test = lr.predict(testX)
print('lr Classifier:\n> Accuracy on training data = {:.4f}\n> Accuracy on test data = {:.4f}'.format(
accuracy_score(y_true=trainY, y_pred=clf_preds_train),
accuracy_score(y_true=testY, y_pred=clf_preds_test)
))
vc.fit(trainX, trainY)
clf_preds_train = vc.predict(trainX)
clf_preds_test = vc.predict(testX)
print('vc Classifier:\n> Accuracy on training data = {:.4f}\n> Accuracy on test data = {:.4f}'.format(
accuracy_score(y_true=trainY, y_pred=clf_preds_train),
accuracy_score(y_true=testY, y_pred=clf_preds_test)
))
#we already fit the grid model in the step above
vc_preds_train = grid.predict(trainX)
vc_preds_test = grid.predict(testX)
print('Voting Classifier with GridSearch:\n> Accuracy on training data = {:.4f}\n> Accuracy on test data = {:.4f}'.format(
accuracy_score(y_true=trainY, y_pred=vc_preds_train),
accuracy_score(y_true=testY, y_pred=vc_preds_test)
))
8 Conclusion
In this post I have shown how to use the Voting Classifier. Furthermore I improved the performance with Grid Search.