- 1 Introduction
- 2 Import the Libraries and the Data
- 3 Gensim - Word2Vec
- 4 Gensim - Doc2Vec
- 5 Gensim - FastText
- 6 Phrases & Phraser
- 7 Use Pre-Trained Models
- 8 Conclusion
1 Introduction
In my last post (NLP - Text Vectorization) I showed how to convert words from a text corpus into real numbers to make them readable for machine learning algorithms. The problem with BoW or TF-IDF vectorization is that the semantics of the word are not encoded in its vector representation. For example, the words “mobile phone” and “cell phone” have similar meanings, but BoW or TF-IDF does not take this into account and ignores the meaning of the words.
And that’s where Word Embedding comes in.
Word embedding is one of the most popular language modeling techniques used to map words onto vectors of real numbers. It is able to represent words or phrases in a vector space with multiple dimensions that have semantic and syntactic similarity. Word embeddings can be created using various methods.
In contrast to BoW or TF-IDF, the word embedding approach vectorizes a word, placing words that have similar meanings closer together. For example, the words “mobile phone” and “cell phone” would have a similar vector representation. This means that when the word is embedded, the meaning of the word is encoded in the vector.
The motivation behind converting text into semantic vectors is that the word embedding method is not only able to extract the semantic relations, but it should also preserve most of the relevant information about a text corpus.
2 Import the Libraries and the Data
import pandas as pd
import numpy as np
import pickle as pk
from nltk.tokenize import word_tokenize
from sklearn.svm import SVC
import statistics
from gensim.models import Word2Vec
from gensim.models import KeyedVectors
from gensim.models.doc2vec import Doc2Vec
from gensim.models.doc2vec import TaggedDocument
from gensim.models import Phrases
from gensim.models.phrases import Phraser
import gensim.downloader as apidf = pd.DataFrame({'Rating': [3,5,1,2],
'Text': ["I love sunflowers",
"Sunflowers fill my heart with joy",
"I love to look into the garden and see the flowers",
"Flowers especially sunflowers are the most beautiful"]})
df
Here I will quickly create tokens from our sample dataset, since Word2Vec from gensim can only do well with them.
df['Text_Tokenized'] = df['Text'].str.lower().apply(word_tokenize)
df
3 Gensim - Word2Vec
Word2Vec from gensim is one of the most popular techniques for learning word embeddings using a flat neural network. It can be used with two methods:
- CBOW (Common Bag Of Words): Using the context to predict a target word
- Skip Gram: Using a word to predict a target context
The corresponding layer structure looks like this:
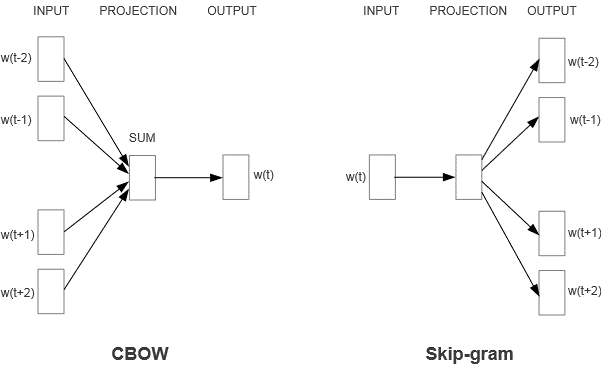
When should which method be used?
CBOW is faster and can therefore be used well for large data sets. In addition, the representation of more frequent words is better than with Skip Gram.
The Skip Gram method works well for smaller data sets and can represent rare words well.
3.1 Instantiation
First of all I instantiate the Word2Vec model. I use the following parameters:
vector_size: Determines the size of the vectors we wantwindow: Determines the number of words before and after the target word to be considered as context for the wordmin_count: Determines the number of times a word must occur in the text corpus for a word vector to be created
The exact meaning of these and other parameters can be read here: GENSIM - Word2vec embeddings
I deliberately assign the vector size (vector_size) to its own variable here, since I will need it again at a later time.
vector_size_n_w2v = 5
w2v_model = Word2Vec(vector_size=vector_size_n_w2v,
window=3,
min_count=1,
sg=0) # 0=CBOW, 1=Skip-gram
print(w2v_model)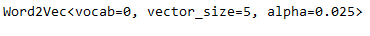
Now the creation of the vocabulary, which is to be learned by Word2Vec, takes place.
w2v_model.build_vocab(df['Text_Tokenized'])
print(w2v_model)
Finally, the neural network is trained (here with the CBOW method) over 5 epochs.
w2v_model.train(df['Text_Tokenized'],
total_examples=w2v_model.corpus_count,
epochs=5)These steps do not necessarily have to be performed individually. If the following syntax is used (with the specification of the text corpus), the creation of the vocabulary as well as the training is carried out automatically.
However, it is recommended to perform the steps separately, as some parameter settings can be made in each case. You can also read all about it here: GENSIM - Word2vec embeddings
vector_size_n_w2v = 5
w2v_model = Word2Vec(df['Text_Tokenized'],
vector_size=vector_size_n_w2v,
window=3,
min_count=1,
sg=0, # 0=CBOW, 1=Skip-gram
epochs=5)
print(w2v_model)
By supplying sentences directly in the original instantiation call, you essentially asked that one call to also do the build_vocab() & train() steps automatically using those sentences.
It is recommended to save the Word2Vec model immediately after a training session, as this is usually a very time-consuming task. Furthermore, I also save the metric that was used for the vector_size parameter.
w2v_model.save("word2vec/word2vec_model")
pk.dump(vector_size_n_w2v, open('word2vec/vector_size_w2v_metric.pkl', 'wb'))3.2 Exploration of the calculated Values
In the following I show a few commands how to display the calculated and stored values.
# The learned vocabulary:
w2v_model.wv.index_to_key
# Length of the learned vocabulary:
len(w2v_model.wv.index_to_key)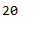
# Output of the calculated vector for a given word from the vocabulary:
w2v_model.wv['sunflowers']
# Length of the calculated vector:
len(w2v_model.wv['sunflowers'])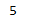
# Display the words that are most similar to a given word from the vocabulary:
w2v_model.wv.most_similar('sunflowers')
3.3 Generation of aggregated Sentence Vectors
Now we will generate aggregate sentence vectors based on the word vectors for each word in the given sentence.
words = set(w2v_model.wv.index_to_key )
df['Text_vect'] = np.array([np.array([w2v_model.wv[i] for i in ls if i in words])
for ls in df['Text_Tokenized']])
df
Since we used min_count=1 in the model training, each word was learned by Word2Vec and got a vector (with length of 5).
Unfortunately, our example sentences have different numbers of words, so the database is correspondingly heterogeneous:
for i, v in enumerate(df['Text_vect']):
print(len(df['Text_Tokenized'].iloc[i]), len(v))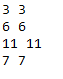
As we can see from the output shown above, the first sentence from the dataset is assigned three vectors (each with a length of 5). This would result in a count of 15 features.
The second sentence would be assigned 30 features (6*5).
However, a machine learning model wants to see a consistent set of features for each example. Currently, a model training error would be thrown out.
To get the number of features equal, the next step is to calculate an element-wise average of the different vectors assigned to a sentence. To explain in more detail how this should work, let’s look at the three vectors of the first sentence:
content_sentence1_Text_vect = list(df['Text_vect'].loc[0:0])
content_sentence1_Text_vect
Each of these word vectors has a size of 5 because we set it that way when we trained our Word2Vec model. Now we will average the first element of these three word vectors and store it as the first entry in our final vector. We do this for all further elements so that we finally get a final vector with length 5 which describes the sentence.
I have listed this calculation manually once for our present example:
element1 = [0.1476101,
-0.03632087,
-0.01072454]
element2 = [-0.03066945,
0.05751216,
0.0047286]
element3 = [-0.09073229,
0.01985285,
0.10206699]
element4 = [0.13108101,
-0.16571797,
0.18018547]
element5 = [-0.09720321,
-0.18894958,
-0.186059]
element1_mean = statistics.mean(element1)
element2_mean = statistics.mean(element2)
element3_mean = statistics.mean(element3)
element4_mean = statistics.mean(element4)
element5_mean = statistics.mean(element5)
manually_calculated_mean_values = [[element1_mean, element2_mean, element3_mean, element4_mean, element5_mean]]
manually_calculated_mean_values_df = pd.DataFrame(manually_calculated_mean_values)
manually_calculated_mean_values_df
This is now the expected output for our first record.
Since I don’t want to do this manual calculation for each record separately (a vector size of 5 is very small and in real life you have more than 4 entries in the data set) I use a for-loop for this.
3.4 Generation of averaged Sentence Vectors
As described above, I will now generate sentence vectors based on the averaging of the word vectors for the words contained in the sentence. If you can remember I assigned the vector size to a separate variable (‘vector_size_n_w2v’) during instantiation. This is needed again in the else statement of the following for-loop.
text_vect_avg = []
for v in df['Text_vect']:
if v.size:
text_vect_avg.append(v.mean(axis=0))
else:
text_vect_avg.append(np.zeros(vector_size_n_w2v, dtype=float)) # the same vector size must be used here as for model training
df['Text_vect_avg'] = text_vect_avg
df
Let’s check again if the vector lengths are now consistent:
# Are our sentence vector lengths consistent?
for i, v in enumerate(df['Text_vect_avg']):
print(len(df['Text_Tokenized'].iloc[i]), len(v))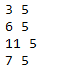
A machine learning algorithm cannot work directly with the column generated above (‘Text_vect_avg’). I have added it to the dataset for completeness. However, I continue to work with the created dictionary ‘text_vect_avg’.
df_Machine_Learning = pd.DataFrame(text_vect_avg)
df_Machine_Learning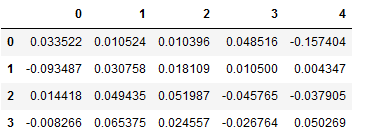
To make this dataset a little prettier, I add names to the columns:
df_Machine_Learning.columns = ['Element_' + str(i+1) for i in range(0, df_Machine_Learning.shape[1])]
df_Machine_Learning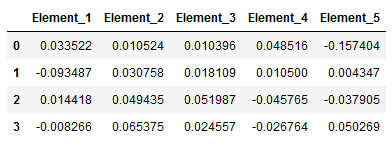
Let’s do a plausibility check again at this point.
In an earlier step, I manually calculated the final vector for the first sentence. Let’s briefly compare the result of the for-loop with the manually calculated result:
df_Machine_Learning.iloc[:1]
manually_calculated_mean_values_df
Fits perfectly.
Now I create my final data set with which I can train a machine learning model in a meaningful way:
final_df = pd.concat([df[['Rating', 'Text']], df_Machine_Learning], axis=1, sort=False)
final_df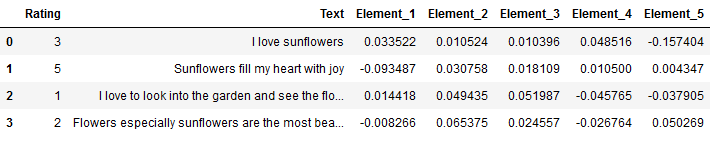
3.5 Model Training
clf = SVC(kernel='linear')
clf.fit(df_Machine_Learning, final_df['Rating'])pk.dump(clf, open('clf_model.pkl', 'wb'))3.6 Processing of new Input
What I would like to show is how to deal with new input, i.e. if you want to use a trained model, so that the predictions can be run.
3.6.1 Load the Word2Vec Model
w2v_model_reloaded = Word2Vec.load("word2vec/word2vec_model")
vector_size_n_reloaded = pk.load(open("word2vec/vector_size_w2v_metric.pkl",'rb'))
print(w2v_model_reloaded)
print(vector_size_n_reloaded)
3.6.2 Load the new Input
new_input = ["Flowers I like to see in the park especially sunflowers",
"I like flowers"]
print(new_input[0])
print(new_input[1])
It makes sense to transfer it to a dataframe if you don’t get the data that way anyway.
new_input_df = pd.DataFrame(new_input, columns=['New_Input'])
new_input_df
3.6.3 Pre-Processing of the new Input
Let’s apply the steps shown earlier to the new dataset as well so we can use the ML model.
new_input_df['New_Input_Tokenized'] = new_input_df['New_Input'].str.lower().apply(word_tokenize)
new_input_df
words = set(w2v_model_reloaded.wv.index_to_key )
new_input_df['New_Input_vect'] = np.array([np.array([w2v_model_reloaded.wv[i] for i in ls if i in words])
for ls in new_input_df['New_Input_Tokenized']])
new_input_df
for i, v in enumerate(new_input_df['New_Input_vect']):
print(len(new_input_df['New_Input_Tokenized'].iloc[i]), len(v))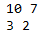
Here we see now that only 7 out of 10 (or 2 out of 3 in the second sentence) words were already learned by Word2Vec and only accordingly many word vectors were merged in the column ‘New_Input_vect’.
text_vect_avg = []
for v in new_input_df['New_Input_vect']:
if v.size:
text_vect_avg.append(v.mean(axis=0))
else:
text_vect_avg.append(np.zeros(vector_size_n_reloaded, dtype=float)) # the same vector size must be used here as for model training
new_input_df['New_Input_vect_avg'] = text_vect_avg
new_input_df
for i, v in enumerate(new_input_df['New_Input_vect_avg']):
print(len(new_input_df['New_Input_Tokenized'].iloc[i]), len(v))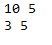
Fits, the final vector length is uniform again.
new_input_Machine_Learning_df = pd.DataFrame(text_vect_avg)
new_input_Machine_Learning_df.columns = ['Element_' + str(i+1) for i in range(0, new_input_Machine_Learning_df.shape[1])]
new_input_Machine_Learning_df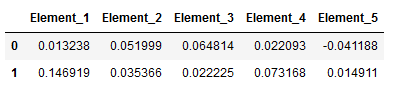
final_new_input_df = pd.concat([new_input_df[['New_Input']], new_input_Machine_Learning_df], axis=1, sort=False)
final_new_input_df
3.6.4 Model Predictions
Okay, now we are ready to receive the predictions.
clf_reloaded = pk.load(open("clf_model.pkl",'rb'))
y_pred = clf_reloaded.predict(new_input_Machine_Learning_df)
y_predfinal_new_input_df['Prediction'] = y_pred
final_new_input_df
3.7 Updating the Word2Vec Model
After all, it is not uncommon to want to regularly improve your existing model. Word2Vec offers a simple solution for this.
Let’s assume that the content of the new record (‘new_input_df’) has pleased me quite well and I want to train my existing w2v_model the contained vocabulary.
new_input_df
In the following, I have compared what Word2Vec have already learned with the new vocabulary and found three words that the model does not yet know.
list_new_input = []
for value in new_input_df.New_Input.str.lower().str.split(' '):
list_new_input.extend(value)
set(list_new_input) - set(list(w2v_model_reloaded.wv.index_to_key))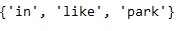
Just a reminder, the current existing vocabulary contains 20 words:
len(w2v_model_reloaded.wv.index_to_key)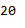
3.7.1 Updating the Weights
First I load the model I want to update.
w2v_model_reloaded = Word2Vec.load("word2vec/word2vec_model")Then I train the Word2Vec model on the new data set (the tokens, since Word2Vec can only handle this).
Make sure that you specify the correct length / the length of the correct dataset, because this step was not necessary before during instantiation.
w2v_model_reloaded.train(new_input_df['New_Input_Tokenized'],
total_examples=len(new_input_df),
epochs=10)Let’s look at the length of the new vocabulary:
len(w2v_model_reloaded.wv.index_to_key)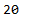
Mhhh… strange. My vocabulary has not changed. But what about the weights of the features and consequently the word vectors?
For this I compare the calculated vector (for the word ‘flowers’) of the model w2v_model and w2v_model_reloaded (which we just updated).
print(w2v_model.wv['flowers'])
print(w2v_model_reloaded.wv['flowers'])
Ok the weights have changed at least.
I also assumed this, since the word ‘flowers’ was present in the learned vocabulary as well as in the newly learned text corpus. What about the vectors for a word that was not included in the new text corpus?
print(w2v_model.wv['sunflowers'])
print(w2v_model_reloaded.wv['sunflowers'])
Here the vectors remained the same. However, this should not have been mandatory, because finally the semantic relation of several words is considered in Word2Vec. Even if a word is not necessarily relearned, its vector(s) can still be influenced by the newly added words.
But how do I now also adapt the vocabulary?
3.7.2 Updating the Weights and the Vocabulary
Also for this I reload the Word2Vec model, because each execution of a learning process (which the weights updated) is kept.
w2v_model_reloaded = Word2Vec.load("word2vec/word2vec_model")In order to also include the new vocabulary to the existing one, you need to apply the .build_vocab() function before retraining.
w2v_model_reloaded.build_vocab(new_input_df['New_Input_Tokenized'], update=True)
print(w2v_model_reloaded)
Perfect, that worked (see ‘vocab=23’).
Now the training can be started to adjust the weights of the features as well.
It is no longer necessary to pay explicit attention to the total_examples parameter as in the previous chapter, since this information is already given by the instantiation and can be retrieved using .corpus_count.
w2v_model_reloaded.train(new_input_df['New_Input_Tokenized'],
total_examples=w2v_model_reloaded.corpus_count,
epochs=20)Let’s compare again the calculated vectors of the models w2v_model and w2v_model_reloaded for the word ‘flowers’:
print(w2v_model.wv['flowers'])
print(w2v_model_reloaded.wv['flowers'])
Great, the vectors have adjusted again.
And what about the vectors for ‘sunflowers’?
print(w2v_model.wv['sunflowers'])
print(w2v_model_reloaded.wv['sunflowers'])
This time there was also an adjustment, because the newly learned vocabulary has created new word contexts and these have influenced the new calculation of the vectors.
3.8 Final saving of the Word2Vec Model
3.8.1 Saving the entire Model
If you want to continue the model training at a later time, you have to save the complete model (as shown before):
w2v_model_reloaded.save("word2vec/w2v_model_updated")3.8.2 Saving the KeyedVectors
If the model training is completely finished and should not be repeated / updated, it is recommended to save only the KeyedVectors, which contain the calculated vectors of the learned vocabulary.
A trained Word2Vec model can reach a very high memory capacity very quickly. KeyedVectors, on the other hand, are much smaller and faster objects that can be used to load the required vectors very quickly while conserving memory.
w2v_model_reloaded_vectors = w2v_model_reloaded.wv
w2v_model_reloaded_vectors.save("word2vec/w2v_model_vectors_updated")Ok, let’s reload it once:
w2v_model_vectors_reloaded = KeyedVectors.load("word2vec/w2v_model_vectors_updated", mmap='r')
print(w2v_model_vectors_reloaded)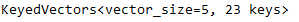
Be aware that from now on the additional argument .wv is no longer needed.
w2v_model_vectors_reloaded['sunflowers']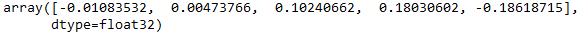
Here again for comparison that the same values have been saved:
w2v_model_reloaded.wv['sunflowers']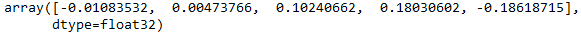
4 Gensim - Doc2Vec
Ok now we are familiar with Word2Vec and how it works…. but what is Doc2Vec??
Once you understand what Word2Vec is, the concept of Doc2Vec is very easy to understand. A Doc2Vec model is based on Word2Vec, with only one more vector added to the neural network for input, the paragraph ID. Accordingly, Doc2vec also uses an unsupervised learning approach to learn document representation like Word2Vec. Look at the following diagram of the layer structure:
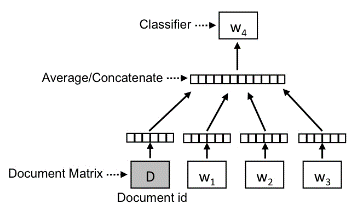
The diagram shown above is based on the layer structure of the CBOW model and is called distributed Memory version of Paragraph Vector (PV-DM).
But instead of using only nearby words to predict the target word, another feature vector is added which is document specific. So when training the word vectors W, the document vector D is trained as well, and in the end of training, it holds a numeric representation of the document. Thus, when the word vectors W are trained, the document vector D is also trained, which contains a numerical representation of the document at the end of the training.
The counterpart of the PV-DM is called Distributed Bag of Words Version of Paragraph Vector (PV-DBOW) and is based on the Skip-Gram approach.
Since PV-DM is most commonly used in practice, I will limit myself to this method in this post. Furthermore, the way it works is very similar to the Word2Vec model I described in great detail above, so I won’t go into each step again in the following.
I load the same data set as for Word2Vec as the data basis:
df_doc2vec = pd.DataFrame({'Rating': [3,5,1,2],
'Text': ["I love sunflowers",
"Sunflowers fill my heart with joy",
"I love to look into the garden and see the flowers",
"Flowers especially sunflowers are the most beautiful"]})
df_doc2vec
df_doc2vec['Text_Tokenized'] = df_doc2vec['Text'].str.lower().apply(word_tokenize)
df_doc2vec
4.1 Instantiation
The TaggedDocument function helps us to create an input format suitable for the Doc2Vec algorithm. This results in a list of words (tokens) associated with a particular tag (paragraph ID). This results in the additional feature vector mentioned earlier that benefits model training.
Again I assign the vector_size to a separate variable.
vector_size_n_d2v = 5
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(df_doc2vec['Text_Tokenized'])]
d2v_model = Doc2Vec(documents,
vector_size=vector_size_n_d2v,
window=3,
min_count=1,
dm=1, # 0=PV-DBOW, 1=PV-DM
epochs=5)# Length of the learned vocabulary:
len(d2v_model.wv.index_to_key)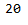
# Saving the model as well as the required parameters
d2v_model.save("doc2vec/doc2vec_model")
pk.dump(vector_size_n_d2v, open('doc2vec/vector_size_d2v_metric.pkl', 'wb'))4.2 Updating the Doc2Vec Model
Again, I use the same example data set as for Word2Vec.
new_input_doc2vec = ["Flowers I like to see in the park especially sunflowers", "I like flowers"]
new_input_doc2vec = pd.DataFrame(new_input_doc2vec, columns=['New_Input'])
new_input_doc2vec['New_Input_Tokenized'] = new_input_doc2vec['New_Input'].str.lower().apply(word_tokenize)
new_input_doc2vec
d2v_model_reloaded = Doc2Vec.load("doc2vec/doc2vec_model")
vector_size_n_d2v_reloaded = pk.load(open("doc2vec/vector_size_d2v_metric.pkl",'rb'))# Learning the vocabulary
documents = [TaggedDocument(doc, [i]) for i, doc in enumerate(new_input_doc2vec['New_Input_Tokenized'])]
d2v_model_reloaded.build_vocab(documents, update=True)len(d2v_model_reloaded.wv.index_to_key)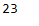
#Training the model again
d2v_model_reloaded.train(documents,
total_examples=d2v_model_reloaded.corpus_count,
epochs=20)Here are the calculated vectors of the different models for the word ‘sunflowers’ for comparison:
print(w2v_model.wv['sunflowers'])
print(d2v_model.wv['sunflowers'])
print(w2v_model_reloaded.wv['sunflowers'])
print(d2v_model_reloaded.wv['sunflowers'])
The Word2Vec model as well as the Doc2Vec model obtained the same vectors during the first training (5 epochs). Now you might think that the two models work exactly the same. However, this is not the case, since the document tag is included in Doc2Vec. However, this effect is not yet noticeable due to the short training time of 5 epochs.
The two relaoded models were not only updated with the additional sample data set but also trained over more epochs (20). A small difference in the vectors can already be seen here.
4.3 Generation of aggregated Sentence Vectors
The principle how to combine the generated word vectors for a sentence and bring them into the same length I have already described above. Therefore here only the adapted syntax for Doc2Vec.
words = set(d2v_model_reloaded.wv.index_to_key )
new_input_doc2vec['New_Input_vect'] = np.array([np.array([d2v_model_reloaded.wv[i] for i in ls if i in words])
for ls in new_input_doc2vec['New_Input_Tokenized']])
new_input_doc2vec
for i, v in enumerate(new_input_doc2vec['New_Input_vect']):
print(len(new_input_doc2vec['New_Input_Tokenized'].iloc[i]), len(v))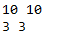
4.4 Generation of averaged Sentence Vectors
text_vect_avg = []
for v in new_input_doc2vec['New_Input_vect']:
if v.size:
text_vect_avg.append(v.mean(axis=0))
else:
text_vect_avg.append(np.zeros(vector_size_n_d2v_reloaded, dtype=float)) # the same vector size must be used here as for model training
new_input_doc2vec['New_Input_vect_avg'] = text_vect_avg
new_input_doc2vec
for i, v in enumerate(new_input_doc2vec['New_Input_vect_avg']):
print(len(new_input_doc2vec['New_Input_Tokenized'].iloc[i]), len(v))
new_input_w2v_Machine_Learning_df = pd.DataFrame(text_vect_avg)
new_input_w2v_Machine_Learning_df.columns = ['Element_' + str(i+1) for i in range(0, new_input_w2v_Machine_Learning_df.shape[1])]
new_input_w2v_Machine_Learning_df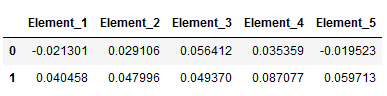
final_new_input_d2v_df = pd.concat([new_input_doc2vec[['New_Input']],
new_input_w2v_Machine_Learning_df],
axis=1, sort=False)
final_new_input_d2v_df
4.5 Final saving of the Doc2Vec Model
Again, with Doc2Vec I have the two options of either saving the entire model (if I want to continue with the training at another time) or saving only the calculated vectors:
Saving the entire Model
d2v_model_reloaded.save("doc2vec/d2v_model_updated")Saving the KeyedVectors
d2v_model_reloaded_vectors = d2v_model_reloaded.wv
d2v_model_reloaded_vectors.save("doc2vec/d2v_model_vectors_updated")That’s it.
5 Gensim - FastText
You are also encouraged to read through the documentation of how FastText works. FastText is another extremely useful word embedding and text classification module developed by Facebook that has already achieved excellent results on many NLP problems and it works pretty much the same way as Word2Vec and Doc2Vec.
6 Phrases & Phraser
6.1 Detecting Phrases
GENSIM includes some useful features that can simplify / improve a model training of Word2Vec or Doc2Vec. One of them is Phrase detection
It can be used to easily find and replace bigrams or trigrams in a text corpus. This can be an incredible booster for the Word2Vec model when creating vectors.
Let’s have a look at the following example dataframe:
df_phrases = pd.DataFrame({'Text': ["I love machine learning it is state of the art",
"Machine learning is pretty famous in new york",
"New york is the place to be for machine learning",
"New york for machine learning"]})
df_phrases
df_phrases['Text_Tokenized'] = df_phrases['Text'].str.lower().apply(word_tokenize)
df_phrases
After tokenization of the data set, the phrase model can now be trained. The two parameters I use are:
min_count: Ignore all words whose total number of words found in the text corpus is less than this valuethreshold: Determines the formation of the phrases based on their achieved score. A higher value means fewer phrases.
You can read these and other parameters here: gensim.models.phrases.Phrases
bigram_phrases = Phrases(df_phrases['Text_Tokenized'],
min_count=2,
threshold=2)If you want to detect not only bigrams but also trigrams in your text corpus use the following code:
trigram_phrases = Phrases(bigram_phrases)
Let’s see what bigrams were found and learned:
print('Number of bigrams learned: ' + str(len(bigram_phrases.export_phrases())))
print()
print('Learned bigrams:')
print(bigram_phrases.export_phrases())
You can transfer the found bigrams into a dataframe with the following code:
dct_bigrams = {k:[v] for k,v in bigram_phrases.export_phrases().items()}
df_bigrams = pd.DataFrame(dct_bigrams).T.reset_index()
df_bigrams.columns = ['bigram', 'score']
df_bigrams
Why am I taking this step?
It is not so easy to determine min_count and threshold at the beginning.
This way you can see by filtering and sorting which scoring the bigrams (or trigrams) have received and adjust these parameters if necessary.
Let’s briefly preview what the new sentences from our sample dataset would look like if we applied the trained phrases model:
# Preview:
for i in range(0,len(df_phrases)):
print(bigram_phrases[df_phrases['Text_Tokenized'][i]])
Note: I will show the saving of the model(s) and the creation of a final dataset at a later time.
6.2 Updating the Phrases Model
Like the Word2Vec/Doc2Vec model, the Phrases model can be updated with new input. I will show you how to do this in this chapter. Here we have a new data set:
df_phrases_new_input = pd.DataFrame({'Text': ["Data Science becomes more and more popular",
"For Data Science task you need machnine learning algorithms",
"The buzzword 2020 is Data Science"]})
df_phrases_new_input
df_phrases_new_input['Text_Tokenized'] = df_phrases_new_input['Text'].str.lower().apply(word_tokenize)
df_phrases_new_input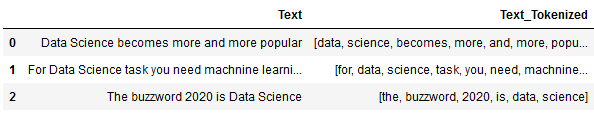
The add_vocab function can be used to update the existing model:
bigram_phrases.add_vocab(df_phrases_new_input['Text_Tokenized'])Now let’s look again at what bigrams were learned from the model:
print('Number of bigrams learned: ' + str(len(bigram_phrases.export_phrases())))
print()
print('Learned bigrams:')
print(bigram_phrases.export_phrases())
Perfect, a new bigram (‘machine_learning’) was learned.
6.3 Safe & Load
As with Word2Vec/Doc2Vec, we can save the Phrases model and reload it at a later time as well as re-train /update it.
Phrases:
bigram_phrases.save("bigram_phrases")bigram_phrases_relaod = Phrases.load("bigram_phrases")print('Number of bigrams learned: ' + str(len(bigram_phrases_relaod.export_phrases())))
print()
print('Learned bigrams:')
print(bigram_phrases_relaod.export_phrases())
Phraser:
If we don’t want to train the model further, we can use Phraser to save memory and increase speed.
bigram_phraser = Phraser(bigram_phrases)
bigram_phraser.save("bigram_phraser")bigram_phraser_reload = Phraser.load("bigram_phraser")# Check if relaoded phraser still work
sentence = ["I live in new york"]
sentence_stream = [doc.split(" ") for doc in sentence]
bigram_phraser_reload.find_phrases(sentence_stream)
6.4 Creation of the final dataframe
As soon as I am done with the Phrases model training, I will exclusively use the created Phraser model.
test_new_input = pd.DataFrame({'Text': ["Data Science especially machine learning in New York is a total hype"]})
test_new_input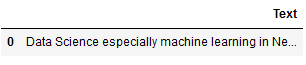
test_new_input['Text'][0]
test_new_input['Text_Tokenized'] = test_new_input['Text'].str.lower().apply(word_tokenize)
test_new_input
bigram_phraser.find_phrases(test_new_input['Text_Tokenized'])
All three learned bigrams also appear in our example here and are correctly detected by the model.
Now I want to create a final dataset that contains the bigrams instead of the individual words in the text corpus.
I use the following function for this purpose:
def make_bigrams_func(text):
'''
Replaces single words by found bigrams
The bigram model 'bigram_phraser' must be loaded
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with inserted bigrams
'''
return [bigram_phraser[doc] for doc in text]test_new_input['Text_Tokenized_bigrams'] = make_bigrams_func(test_new_input['Text_Tokenized'])
test_new_input
test_new_input['Text_Tokenized_bigrams'][0]
Perfect, our new text corpus now contains the bigrams found instead of the individual words.
Now I could train a Word2Vec or Doc2Vec model on this data basis, which would probably generate better values of the vectors.
7 Use Pre-Trained Models
Especially in the field of NLP it is very difficult to get a sufficiently large data base in the beginning to be able to do a meaningful model training.
What has proven to be extremely useful in solving many NLP problems is the use of pre-trained models.
Gensim offers a wide range of pre-trained models:
list(api.info()['models'].keys())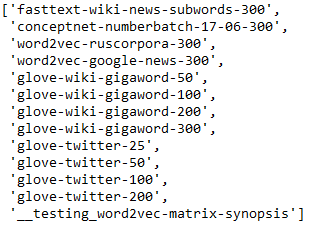
Let’s load one of them:
glove_vectors = api.load('glove-wiki-gigaword-50')Ok let’s see if our vocabulary is also already included in it:
glove_vectors['sunflowers']
glove_vectors.most_similar('sunflowers', topn=5)
Yes it is. So we can make life easy for ourselves and use the already calculated vectors of ‘glove-wiki-gigaword-50’.
8 Conclusion
In this post I went into detail about using Word2Vec and Doc2Vec from the python library gensim to solve text classification problems.
Furthermore, I have shown how the Phrases module can be used to further improve the data basis.
The final folder structure should now look like this: