{kind=link}
{kind=link}
1 Introduction
New year new topic!
I would like to start the new year 2021 with a topic that I have been working on for a while but have not yet found the time to write a post about it: Computer Vision !
In a nutshell:
Computer vision attempts to process and analyze images captured by cameras in a variety of ways to understand their content or extract geometric information.
We will come to the topic of how to build neural networks to solve computer vision problems. Before such a model training, a lot of preparatory work is needed, such as the collection and preparation of data or the handling of files.
Since I already had a lot to do with computer vision and it was too stupid for me to do the repetitive tasks manually, I automated some steps. And that’s what this post is about.

For this post, I used the images from the cats and dogs dataset from the statistics platform “Kaggle”. You can download the used data from my “GitHub Repository”.
2 Import the libraries
import os
import docx2txt
from PIL import Image
import glob
import shutil
import random3 Definition of required functions
def createFolder(directory):
'''
Creates a folder in the place of the root directory
Args:
directory (string): Name that should be given to the created folder
Returns:
New folder at the current directory
'''
try:
if not os.path.exists(directory):
os.makedirs(directory)
except OSError:
print ('Error: Creating directory. ' + directory)4 Extract Images from .docx (+renaming)
Imagine we have one or more word documents that contain images. I have two such files here at my root directory:
Let’s have a look at the cats_pic.docx:

And also a look at the dogs_pic.docx:

We now want to extract these images and place them in an appropriate folder.
4.1 Extract and rename Cats Images
This creates a new folder (‘cats’) at the root directory and saves the extracted images from the word file there.
createFolder('./cats/')
text = docx2txt.process("cats_pic.docx", "cats")Now we want to rename the extracted images accordingly.
Make sure that the images in the Word file are really in jpg format. If they are png images, the following command must be changed accordingly.
os.getcwd()
name_of_pic_folder = "cats"
Text = "cat"
for i, filename in enumerate(os.listdir(name_of_pic_folder)):
os.rename(name_of_pic_folder + "/" + filename, name_of_pic_folder + "/" + Text + str(i+1) + ".jpg")Let’s see how many images we have extracted.
print('Number of cat pictures:', len(os.listdir('cats')))
4.2 Extract and rename Dogs Images
Now we do the same with the dogs_pic file.
createFolder('./dogs/')
text = docx2txt.process("dogs_pic.docx", "dogs")os.getcwd()
name_of_pic_folder = "dogs"
Text = "dog"
for i, filename in enumerate(os.listdir(name_of_pic_folder)):
os.rename(name_of_pic_folder + "/" + filename, name_of_pic_folder + "/" + Text + str(i+1) + ".jpg")print('Number of dog pictures:', len(os.listdir('dogs')))
4.3 Current folder structure
Our current folder structure looks like this:

5 Convert Images from .png to .jpg
Currently we have 95 images in both folders (cats and dogs).
These are still too few. Fortunately, I have a few more pictures of dogs and cats, which can be added to the current record. You can also download this data from my “GitHub Repository”.
However, these are saved in a different format (png).
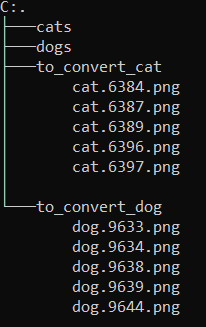
Since I prefer a consistent file format for my model training, I now want to convert the additional images from png to jpg.
I advise a conversion only in this direction because you should not convert jpg’s to png’s. A neural network can also be trained based on png, but since most of the images are in jpg format anyway, I convert the small amount of png images to have a unified data base.
5.1 Convert Images
Cats file:
pngs = glob.glob('./to_convert_cat/*.png')
for j in pngs:
im = Image.open(j)
im.save(j[:-3] + 'jpg')Dogs file:
pngs = glob.glob('./to_convert_dog/*.png')
for j in pngs:
im = Image.open(j)
im.save(j[:-3] + 'jpg')5.2 Delete .png files
Now that we have converted the images to jpg’s we no longer need the png files. So I will let Python delete them:
Delete cats.png’s:
mydir = 'to_convert_cat'
filelist = [ f for f in os.listdir(mydir) if f.endswith(".png") ]
for f in filelist:
os.remove(os.path.join(mydir, f))Delete dogs.png’s:
mydir = 'to_convert_dog'
filelist = [ f for f in os.listdir(mydir) if f.endswith(".png") ]
for f in filelist:
os.remove(os.path.join(mydir, f))5.3 Rename .jpg’s accordingly
Now I would like to rename the newly created jpg’s accordingly. I have already named and numbered the images extracted from the Word documents accordingly. At this point I would like to continue with the naming of the newly generated data.
os.getcwd()
name_of_pic_folder = "to_convert_cat"
Text = "cat"
current_length_cats = len(os.listdir('cats'))
for i, filename in enumerate(os.listdir(name_of_pic_folder)):
os.rename(name_of_pic_folder + "/" + filename,
name_of_pic_folder + "/" + Text + str(i+1+current_length_cats) + ".jpg")os.getcwd()
name_of_pic_folder = "to_convert_dog"
Text = "dog"
current_length_dogs = len(os.listdir('dogs'))
for i, filename in enumerate(os.listdir(name_of_pic_folder)):
os.rename(name_of_pic_folder + "/" + filename,
name_of_pic_folder + "/" + Text + str(i+1+current_length_dogs) + ".jpg")Here is the result:
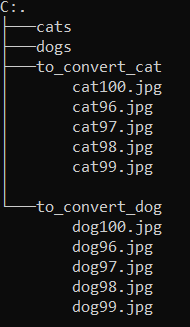
5.4 Copy all new Images to main folders
Now we have to move the images to the main folders to complete the dataset.
src_dir = "to_convert_cat"
dst_dir = "cats"
for jpgfile in glob.iglob(os.path.join(src_dir, "*.jpg")):
shutil.copy(jpgfile, dst_dir)src_dir = "to_convert_dog"
dst_dir = "dogs"
for jpgfile in glob.iglob(os.path.join(src_dir, "*.jpg")):
shutil.copy(jpgfile, dst_dir)6 Train-Validation-Test Split
To prepare a model training, the data must be divided accordingly. If I want to create a model for image classification I need three parts:
- Training Part
- Validation Part
- Test Part
The automatic splitting of the image data with corresponding proportions will be done in the following. Let’s have a look at the final number of pictures:
print('Final number of cat pictures:', len(os.listdir('cats')))
print('Final number of dog pictures:', len(os.listdir('dogs')))
We have previously taken care to name each category appropriately (category name with sequential number). This benefits us at this point.
We now look at the length of the final records per category and store their numbers in a list.
# Get length of cats dataset
final_length_cats = len(os.listdir('cats'))
list_cats_full = list(range(1, final_length_cats+1))
print('First 5 Elements of list_cats :' + str(list_cats_full[0:5]))
print('Last 5 Elements of list_cats :' + str(list_cats_full[-5:]))
# Get length of dogs dataset
final_length_dogs = len(os.listdir('dogs'))
list_dogs_full = list(range(1, final_length_dogs+1))
print('First 5 Elements of list_dogs :' + str(list_dogs_full[0:5]))
print('Last 5 Elements of list_dogs :' + str(list_dogs_full[-5:]))
Now we determine the proportions in which the division should take place:
# Determine the proportions of train, validation and test part
train_part_proportion = 0.8
validation_part_proportion = 0.1
test_part_proportion = 0.16.1 Determine Images
We have now created/determined our necessary lists and the distribution proportions.
Now we create more lists with numbers of images to be used for the three parts (train, validation and test) according to their predefined proportions.
If you are wondering why the following sequence (first the determination of the test part, then the validation part and finally the training part) was chosen by me, this is because I select random images for the test and validation part from the complete data set according to the defined proportion and also remove them from the list of available images so that no images are used twice by chance (for example, the same image is selected for the test and the training part). After selecting the randomly chosen images for the test and validation part, n images remain, which then represent the final training part.
6.1.1 Test Part
for cats dataset
list_cats_test = random.sample(list_cats_full, round(len(list_cats_full)*test_part_proportion))
list_cats_test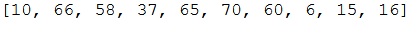
list_remaining_cat_images = [item for item in list_cats_full if item not in list_cats_test]
len(list_remaining_cat_images)
for dogs dataset
list_dogs_test = random.sample(list_dogs_full, round(len(list_dogs_full)*test_part_proportion))
list_dogs_test
list_remaining_dog_images = [item for item in list_dogs_full if item not in list_dogs_test]
len(list_remaining_dog_images)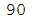
6.1.2 Validation Part
list_cats_validation = random.sample(list_remaining_cat_images,
round(len(list_cats_full)*validation_part_proportion))
list_cats_validation
list_dogs_validation = random.sample(list_remaining_dog_images,
round(len(list_dogs_full)*validation_part_proportion))
list_dogs_validation
6.1.3 Train Part
list_cats_training = [item for item in list_remaining_cat_images if item not in list_cats_validation]
len(list_cats_training)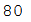
list_dogs_training = [item for item in list_remaining_dog_images if item not in list_dogs_validation]
len(list_dogs_training)
Now we have the randomly selected images for each category (cats, dogs) for the training, the validation and the testing part.
6.2 Setting the folder structure
Now that we have determined the images for their appropriate use, we set up an adequate folder structure in which we will store the images.
This looks like a lot of code now but I have commented every single step in the code.
# Get root directory
root_directory = os.getcwd()
# Define original datasets direction
original_dataset_dir_cats = os.path.join(root_directory, 'cats')
original_dataset_dir_dogs = os.path.join(root_directory, 'dogs')
# Define base direction
# This is the place where the image splitting
# (train, validation, test) should take place.
base_dir = os.path.join(root_directory, 'cats_and_dogs')
os.mkdir(base_dir)# Define general train, validation and test direction
train_dir = os.path.join(base_dir, 'train')
os.mkdir(train_dir)
validation_dir = os.path.join(base_dir, 'validation')
os.mkdir(validation_dir)
test_dir = os.path.join(base_dir, 'test')
os.mkdir(test_dir)# Define train direction for cats
train_cats_dir = os.path.join(train_dir, 'cats')
os.mkdir(train_cats_dir)
# Define train direction for dogs
train_dogs_dir = os.path.join(train_dir, 'dogs')
os.mkdir(train_dogs_dir)# Define validation direction for cats
validation_cats_dir = os.path.join(validation_dir, 'cats')
os.mkdir(validation_cats_dir)
# Define validation direction for dogs
validation_dogs_dir = os.path.join(validation_dir, 'dogs')
os.mkdir(validation_dogs_dir)# Define test direction for cats
test_cats_dir = os.path.join(test_dir, 'cats')
os.mkdir(test_cats_dir)
# Define test direction for dogs
test_dogs_dir = os.path.join(test_dir, 'dogs')
os.mkdir(test_dogs_dir)The created folder structure in the root directory now looks like this
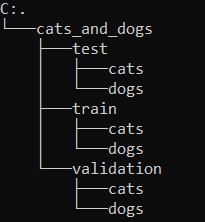
6.3 Copying the determined images to the appropriate folders
Now we will distribute the previously determined images to the folders accordingly.
6.3.1 Train Part
fnames = ['cat{}.jpg'.format(i) for i in list_cats_training]
for fname in fnames:
src = os.path.join(original_dataset_dir_cats, fname)
dst = os.path.join(train_cats_dir, fname)
shutil.copyfile(src, dst)fnames = ['dog{}.jpg'.format(i) for i in list_dogs_training]
for fname in fnames:
src = os.path.join(original_dataset_dir_dogs, fname)
dst = os.path.join(train_dogs_dir, fname)
shutil.copyfile(src, dst)6.3.2 Validation Part
fnames = ['cat{}.jpg'.format(i) for i in list_cats_validation]
for fname in fnames:
src = os.path.join(original_dataset_dir_cats, fname)
dst = os.path.join(validation_cats_dir, fname)
shutil.copyfile(src, dst)fnames = ['dog{}.jpg'.format(i) for i in list_dogs_validation]
for fname in fnames:
src = os.path.join(original_dataset_dir_dogs, fname)
dst = os.path.join(validation_dogs_dir, fname)
shutil.copyfile(src, dst)6.3.3 Test Part
fnames = ['cat{}.jpg'.format(i) for i in list_cats_test]
for fname in fnames:
src = os.path.join(original_dataset_dir_cats, fname)
dst = os.path.join(test_cats_dir, fname)
shutil.copyfile(src, dst)fnames = ['dog{}.jpg'.format(i) for i in list_dogs_test]
for fname in fnames:
src = os.path.join(original_dataset_dir_dogs, fname)
dst = os.path.join(test_dogs_dir, fname)
shutil.copyfile(src, dst)6.4 Final Check
Now that we have copied the images accordingly, let’s take a final look at the distribution:
print('Total training cat images:', len(os.listdir(train_cats_dir)))
print('Total training dog images:', len(os.listdir(train_dogs_dir)))
print()
print('Total validation cat images:', len(os.listdir(validation_cats_dir)))
print('Total validation dog images:', len(os.listdir(validation_dogs_dir)))
print()
print('Total test cat images:', len(os.listdir(test_cats_dir)))
print('Total test dog images:', len(os.listdir(test_dogs_dir)))
That’s it. Now we are ready for model training.
7 Conclusion
In this post I showed how to extract images from word files and rename them accordingly. Also the conversion of the file formats was covered. Lastly, I showed how to usefully divide the available image data for model training.
In my following post, I will use the images prepared here and show how to create an image classification model using neural networks.
Check out these publications: