1 Introduction
In my last post I showed a “simple ETL”. Now we go one step further and add a join after the data has been processed.
Overview of the ETL steps:
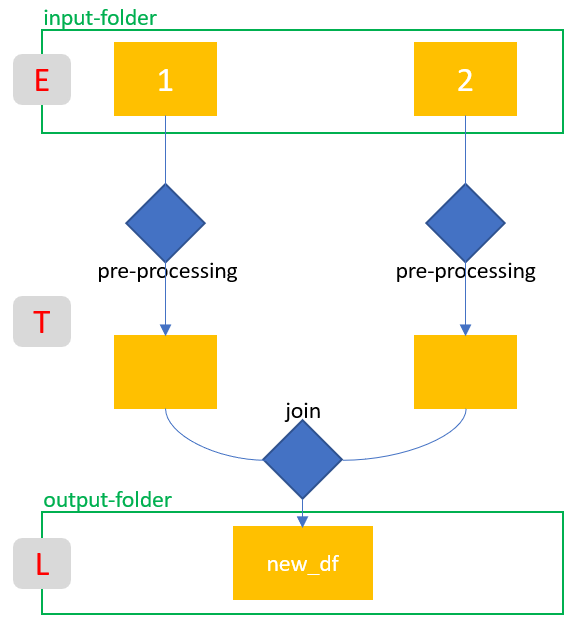
At the end I will test the created ETL. I will show this from another jupyter notebook and a fully automatic call from the command line.
For this post I use two specially created sample data sets. A copy of them is stored in my “GitHub Repo”.
2 Setup
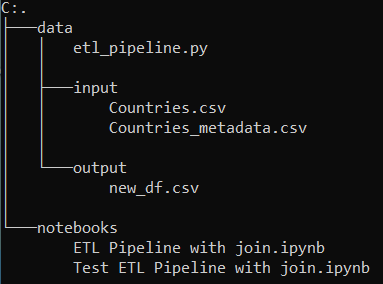
The setup is nearly the same as I described for the “simple ETL”. The files are always stored in the same way. Only the output from the ETL is different this time, because I don’t have both edited original files returned to me but only the merged new data set.
3 ETL Pipeline with join
Here I show again the single steps which I transfer into an ETL again.
import pandas as pd3.1 Extract
countries = pd.read_csv('../data/input/Countries.csv')
countries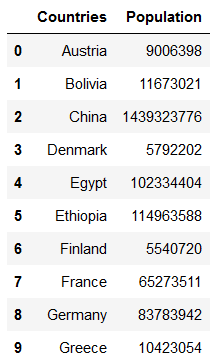
countries_metadata = pd.read_csv('../data/input/Countries_metadata.csv')
countries_metadata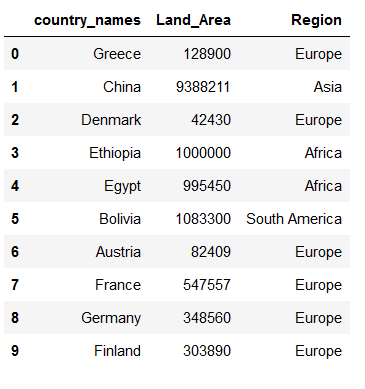
3.2 Transform
countries['Population'] = countries['Population']/1000
countries = countries.rename(columns={'Population':'Population_per_k'})
countries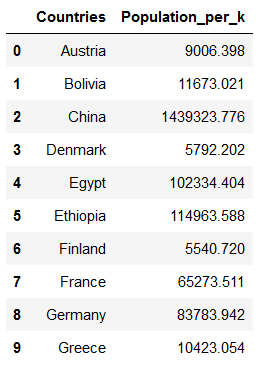
countries_metadata['Land_Area'] = countries_metadata['Land_Area']/1000
countries_metadata = countries_metadata.rename(columns={'Land_Area':'Land_Area_per_k'})
countries_metadata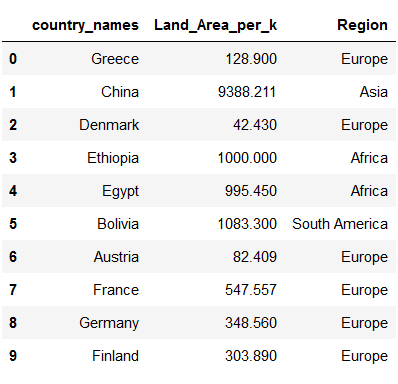
new_df = pd.merge(countries, countries_metadata, left_on='Countries', right_on='country_names', how='left')
new_df = new_df.drop(['country_names'], axis=1)
new_df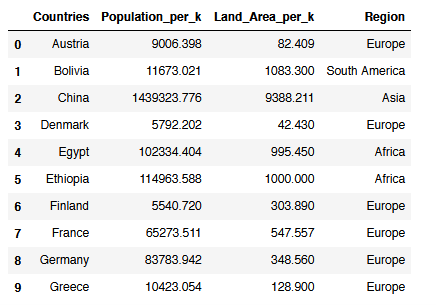
3.3 Load
new_df.to_csv('../data/output/new_df.csv')4 Create etl_pipeline.py
import pandas as pd
import numpy as np
import os
class DataPreprocessor:
def __init__(self, path_folder = "path/to/data"):
self.path_folder = path_folder
# Path to input
self.path_input_folder = "{}/input/".format(path_folder)
self.path_input_countries = self.path_input_folder + 'Countries.csv'
self.path_input_countries_metadata = self.path_input_folder + 'Countries_metadata.csv'
# Path on which output tables are saved
self.path_output_folder = "{}/output/".format(path_folder)
self.path_output_countries = self.path_output_folder + 'Countries.csv'
self.path_output_countries_metadata = self.path_output_folder + 'Countries_metadata.csv'
self.path_output_new_df = self.path_output_folder + 'new_df.csv'
# create dictionaries for read dtypes
self.read_dtypes_countries = {'Countries':'category'}
self.read_dtypes_countries_metadata = {'country_names':'category'}
self.read_dtypes_new_df = {'Countries':'category'}
# create folders for output if not existent yet
if not os.path.exists(self.path_output_folder):
os.makedirs(self.path_output_folder)
def read_data_from_raw_input(self):
print("Start:\tRead in countries Dataset")
self.countries = pd.read_csv(self.path_input_countries, dtype=self.read_dtypes_countries)
print("Finish:\tRead in countries Dataset")
print("Start:\tRead in countries_metadata Dataset")
self.countries_metadata = pd.read_csv(self.path_input_countries_metadata, dtype=self.read_dtypes_countries_metadata)
print("Finish:\tRead in countries_metadata Dataset")
def preprocess_data(self, save_preprocess_countries=False, save_preprocess_countries_metadata=False, save_preprocess_new_df=True):
print("Start:\tPreprocessing countries Dataset")
self.preprocess_countries()
print("Finish:\tPreprocessing countries Dataset")
print("Start:\tPreprocessing countries_metadata Dataset")
self.preprocess_countries_metadata()
print("Finish:\tPreprocessing countries_metadata Dataset")
print("Start:\tPreprocessing new_df Dataset")
self.new_df = pd.merge(self.countries, self.countries_metadata, left_on='Countries', right_on='country_names', how='left')
print("Finish:\tPreprocessing new_df Dataset")
if save_preprocess_countries:
print("Start:\tSave countries Dataset to disc")
self.countries.to_csv(self.path_output_countries, index=False)
print("Finish:\tSave countries Dataset to disc")
if save_preprocess_countries_metadata:
print("Start:\tSave countries_metadata Dataset to disc")
self.countries_metadata.to_csv(self.path_output_countries_metadata, index=False)
print("Finish:\tSave countries_metadata Dataset to disc")
if save_preprocess_new_df:
print("Start:\tSave new_df Dataset to disc")
self.new_df.to_csv(self.path_output_new_df, index=False)
print("Finish:\tSave new_df Dataset to disc")
return self.countries, self.countries_metadata, self.new_df
def preprocess_countries(self):
self.countries['Population'] = self.countries['Population']/1000
self.countries = self.countries.rename(columns={'Population':'Population_per_k'})
def preprocess_countries_metadata(self):
self.countries_metadata['Land_Area'] = self.countries_metadata['Land_Area']/1000
self.countries_metadata = self.countries_metadata.rename(columns={'Land_Area':'Land_Area_per_k'})
def read_preprocessed_tables(self):
print("Start:\tRead in modified new_df Dataset")
self.new_df = pd.read_csv(self.path_output_new_df, dtype=self.read_dtypes_countries)
print("Finish:\tRead in modified new_df Dataset")
return self.new_df
def main():
datapreprocesssor = DataPreprocessor()
datapreprocesssor.read_data_from_raw_input()
datapreprocesssor.preprocess_data()
print('ETL has been successfully completed !!')
#if __name__ == '__main__':
# main()We have commented out the main from the ETL pipeline here with ‘#’. Of course, this syntax must not be commented out in the .py file.
Unfortunately the view is not optimal. Therefore I recommend to copy the syntax into a .py file. I prefer “Visual Studio Code” from Microsoft. But I also put the file in my “GitHub Repo” from where you can get it.
5 Test etl_pipeline.py
Now we want to test our created ETL.
5.1 from jupyter notebook
First I want to test the ETL from a notebook. For this we create and start a new notebook in the notebooks-folder with the name ‘Test ETL Pipeline with join.ipynb’.
import sys
# Specifies the file path where the first .py file is located.
sys.path.insert(1, '../data')
import etl_pipelinedatapreprocessor = etl_pipeline.DataPreprocessor()
datapreprocessor.read_data_from_raw_input()
countries, countries_metadata, new_df = datapreprocessor.preprocess_data(save_preprocess_countries=False, save_preprocess_countries_metadata=False, save_preprocess_new_df=True)
new_df = datapreprocessor.read_preprocessed_tables()
new_df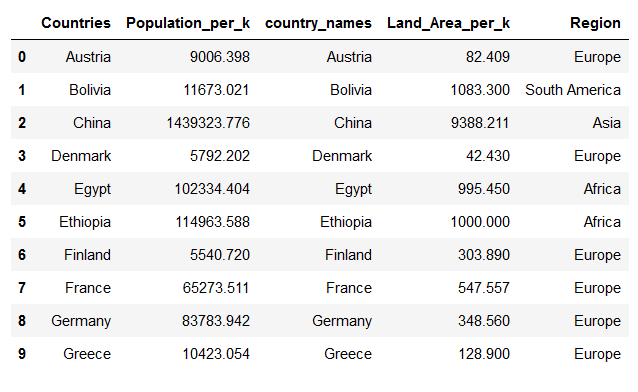
5.2 from command line
Because we have defined a main in the .py file we are able to call and execute the ETL from the command line. It does not matter which command line this is exactly. You can use Anaconda Power Shell, Git Bash, the Windwos Comman Line or anything else.
Type only the following commands in your command prompt:
cd "path/to/your/data/folder"
python etl_pipeline.pyHere we go!
6 Conclusion
In this variant of the ETL I have shown how to load two files, apply transformation steps and then merge both datasets to a final dataset. Finally I saved this final dataset in the output folder.