1 Introduction
Now that we have developed a “recommender” based on the film descriptions, we will go a step further in this post and add more metadata.
Unlike collaborative filters, conten-based recommenders do not require data relating to the past activity. Instead they provide recommendations based on a user profile and metadata it has on particular items. However, since content-based systems don’t leverage the power of the community, they often come up with results that are not as impressive or relevant as the ones offered by collaborative filters.
For this post the datasets movies_metadata, keywords and credits from the statistic platform “Kaggle” was used. You can download it from my “GitHub Repository” and here:
2 Import the libraries and the data
import pandas as pd
import numpy as np
import preprocessing_recommender_systems as prs
from ast import literal_eval
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.metrics.pairwise import cosine_similarityAs in the “Plot Description-based Recommender” post I will execute the first pre-processing steps for the main dataset using my stored function in the preprocessing_recommender_systems.py file. This file is also stored on my “GitHub Account” and can be downloaded from there.
df = pd.read_csv('movies_metadata.csv')
df = prs.clean_data(df)
df
Let’s load the other two datasets as well:
cred_df = pd.read_csv('credits.csv')
cred_df.head()
key_df = pd.read_csv('keywords.csv')
key_df.head()
3 Data pre-processing
For the preparation of the data we have to take some steps.
3.1 Clean id column of df
# Function to convert all non-integer IDs to NaN
def clean_ids(x):
try:
return int(x)
except:
return np.nan
#Clean the ids of df
df['id'] = df['id'].apply(clean_ids)
#Filter all rows where ID is not null
df = df[df['id'].notnull()] 3.2 Join the dataframes
Here we get a final dataset with the columns cast, crew and keywords from the last loaded records.
# Convert IDs into integer
df['id'] = df['id'].astype('int')
key_df['id'] = key_df['id'].astype('int')
cred_df['id'] = cred_df['id'].astype('int')
# Merge keywords and credits into our updated metadata dataframe
df = df.merge(cred_df, on='id')
df = df.merge(key_df, on='id')
#Display the head of df
df.head()
3.3 Wrangling crew, cast, keywords and genres
In the following we will work on the columns crew, cast, keywords and genres so that they are usable for the recommender.
# Convert the stringified objects into the native python objects
from ast import literal_eval
features = ['cast', 'crew', 'keywords']
for feature in features:
df[feature] = df[feature].apply(literal_eval)df.head()
In the pre-processing step via preprocessing_recommender_systems.py literal_eval has already been applied to the column genres. For this reason it is not listed in the features here.
Column ‘crew’
Here we are only interested in the director.
#Print the first crew member of the first movie in df
df.iloc[0]['crew'][0]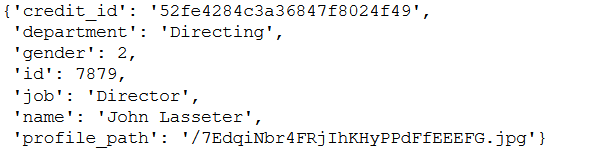
# Extract the director's name. If director is not listed, return NaN
def get_director(x):
for crew_member in x:
if crew_member['job'] == 'Director':
return crew_member['name']
return np.nan#Define the new director feature
df['director'] = df['crew'].apply(get_director)
#Print the directors of the first five movies
df['director'].head()
Column ‘cast’
Here we are interested in the first three cast members.
#Print the first cast member of the first movie in df
df.iloc[0]['cast'][0]
# Returns the list top 3 elements or entire list; whichever is more.
def generate_list(x):
if isinstance(x, list):
names = [i['name'] for i in x]
#Check if more than 3 elements exist. If yes, return only first three. If no, return entire list.
if len(names) > 3:
names = names[:3]
return names
#Return empty list in case of missing/malformed data
return []#Apply the generate_list function to cast
df['cast'] = df['cast'].apply(generate_list)Column ‘keywords’
Here we are interested in the first three keywords.
#Print the first keyword of the first movie in df
df.iloc[0]['keywords'][3]
We can again use the generate_list function here.
#Apply the generate_list function to keywords
df['keywords'] = df['keywords'].apply(generate_list)Column ‘genres’
#Only consider a maximum of 3 genres
df['genres'] = df['genres'].apply(lambda x: x[:3])3.4 Sanitize data
Our current data set looks like this:
# Print the new features of the first 5 movies along with title
df[['title', 'cast', 'director', 'keywords', 'genres']].head()
We will again apply a vectorizer to the text columns, as we did with the Plot Description-based Recommender. In order for it to work correctly, we need to remove the spaces between all the names and keywords (if there are any) and convert them into lowercase.
# Function to sanitize data to prevent ambiguity. It removes spaces and converts to lowercase
def sanitize(x):
if isinstance(x, list):
#Strip spaces and convert to lowercase
return [str.lower(i.replace(" ", "")) for i in x]
else:
#Check if director exists. If not, return empty string
if isinstance(x, str):
return str.lower(x.replace(" ", ""))
else:
return ''#Apply the sanitize function to cast, keywords, director and genres
for feature in ['cast', 'director', 'genres', 'keywords']:
df[feature] = df[feature].apply(sanitize)df[['title', 'cast', 'director', 'keywords', 'genres']].head()
3.5 Create a soup of desired metadata
#Function that creates a soup out of the desired metadata
def create_soup(x):
return ' '.join(x['keywords']) + ' ' + ' '.join(x['cast']) + ' ' + x['director'] + ' ' + ' '.join(x['genres'])# Create the new soup feature
df['soup'] = df.apply(create_soup, axis=1)#Display the soup of the first movie
df.iloc[0]['soup']
3.6 Create vectors with CountVectorizer
# Import CountVectorizer
from sklearn.feature_extraction.text import CountVectorizer
#Define a new CountVectorizer object and create vectors for the soup
count = CountVectorizer(stop_words='english')
count_matrix = count.fit_transform(df['soup'])3.7 Compute the pairwise similarity
#Import cosine_similarity function
from sklearn.metrics.pairwise import cosine_similarity
#Compute the cosine similarity score (equivalent to dot product for tf-idf vectors)
cosine_sim = cosine_similarity(count_matrix, count_matrix)4 Build the Metadata-based Recommender
# Reset index of your df and construct reverse mapping again
df = df.reset_index()
indices = pd.Series(df.index, index=df['title'])# Function that takes in movie title as input and gives recommendations
def content_recommender(title, cosine_sim=cosine_sim, df=df, indices=indices):
# Obtain the index of the movie that matches the title
idx = indices[title]
# Get the pairwsie similarity scores of all movies with that movie
# And convert it into a list of tuples as described above
sim_scores = list(enumerate(cosine_sim[idx]))
# Sort the movies based on the cosine similarity scores
sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True)
# Get the scores of the 10 most similar movies. Ignore the first movie.
sim_scores = sim_scores[1:11]
# Get the movie indices
movie_indices = [i[0] for i in sim_scores]
# Return the top 10 most similar movies
return df['title'].iloc[movie_indices]5 Test the recommender
content_recommender('Toy Story', cosine_sim, df, indices)
6 Conclusion
Done. Now we have designed a recommender that takes into account any amount of additional data such as the participating actors or the director in charge.
References
The content of the entire post was created using the following sources:
Banik, R. (2018). Hands-On Recommendation Systems with Python: Start building powerful and personalized, recommendation engines with Python. Birmingham: Packt Publishing Ltd.