1 Introduction
After Marketing Analytics it is now time to dedicate yourself to a new field of Analytics. As we have already touched on “recommendations in the marketing context”, it makes sense to continue with the topic of recommendation systems at this point.
We will start with a very simple recommender: The Knowledged-based Recommender
Knowledge-based recommenders are used for items that are very rarely bought. It is simply impossible to recommend such items based on past purchasing activity or by building a user profile.
The purchase of real estate is a very good example here. Most of us make such a real estate purchase only once in their lives. Therefore, it is impossible to have historical data in this regard. In such a case, a recommendation system is needed which asks for specific criteria and preferences from the user in order to make appropriate recommendations.
For this post the dataset movies_metadata from the statistic platform “Kaggle” was used. You can download it from my “GitHub Repository”.
2 Import the libraries and the data
import pandas as pd
import numpy as np
from ast import literal_evaldf = pd.read_csv('movies_metadata.csv')
# Select just relevant features
relevant_features = ['title','genres', 'release_date', 'runtime', 'vote_average', 'vote_count']
df = df[relevant_features]
# Print the dataframe
df.head()
3 Data pre-processing
Here we have two tasks to complete. On the one hand we need the release date, which has to be extracted. Second, we have to format the column with the genres it contains so that it fits the recommender.
3.1 Extract the release year
We want to extract year-values from the column relese_date. Therefore we have to convert this column, extract the year, convert the year-column (from float to int) and drop the release_date column.
#Convert release_date into pandas datetime format
df['release_date'] = pd.to_datetime(df['release_date'], errors='coerce')
# Extract year from release_date-column and store the values into a new year-column
df['year'] = pd.DatetimeIndex(df['release_date']).year
#Helper function to convert NaN to 0, if there are any, and all other years to integers.
def convert_int(x):
try:
return int(x)
except:
return 0
#Apply convert_int to the year feature
df['year'] = df['year'].apply(convert_int)
#Drop the release_date column
df = df.drop('release_date', axis=1)
#Display the dataframe
df.head()
3.2 Convert the genres features
Have a look here on the column ‘genres’ of the second movie.
#Print genres of the second movie
df.iloc[1]['genres']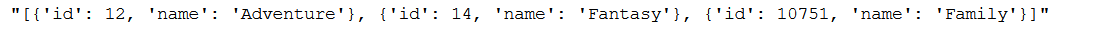
Only the information about the genre needs to be extracted. We can do this as follows:
#Convert all NaN into stringified empty lists
df['genres'] = df['genres'].fillna('[]')
#Apply literal_eval to convert stringified empty lists to the list object
df['genres'] = df['genres'].apply(literal_eval)
#Convert list of dictionaries to a list of strings
df['genres'] = df['genres'].apply(lambda x: [i['name'].lower() for i in x] if isinstance(x, list) else [])
df
Perfect, now we have extracted the genres and saved them in a separate column. Now we want a separate line to be generated for each genre that has been assigned to a film.
#Create a new feature by exploding genres
s = df.apply(lambda x: pd.Series(x['genres']),axis=1).stack().reset_index(level=1, drop=True)
#Name the new feature as 'genre'
s.name = 'genre'
#Create a new dataframe gen_df which by dropping the old 'genres' feature and adding the new 'genre'.
gen_df = df.drop('genres', axis=1).join(s)
#Print the head of the new gen_df
gen_df.head()
Now we are ready to build the Knoledged-based Recommender!
4 Build the Knowledged-based Recommender
def build_chart(gen_df, percentile=0.8):
#Ask for preferred genres
print("Input preferred genre")
genre = input()
#Ask for lower limit of duration
print("Input shortest duration")
low_time = int(input())
#Ask for upper limit of duration
print("Input longest duration")
high_time = int(input())
#Ask for lower limit of timeline
print("Input earliest year")
low_year = int(input())
#Ask for upper limit of timeline
print("Input latest year")
high_year = int(input())
#Define a new movies variable to store the preferred movies. Copy the contents of gen_df to movies
movies = gen_df.copy()
#Filter based on the condition
movies = movies[(movies['genre'] == genre) &
(movies['runtime'] >= low_time) &
(movies['runtime'] <= high_time) &
(movies['year'] >= low_year) &
(movies['year'] <= high_year)]
#Compute the values of C and m for the filtered movies
C = movies['vote_average'].mean()
m = movies['vote_count'].quantile(percentile)
#Only consider movies that have higher than m votes. Save this in a new dataframe q_movies
q_movies = movies.copy().loc[movies['vote_count'] >= m]
#Calculate score using the IMDB formula
q_movies['score'] = q_movies.apply(lambda x: (x['vote_count']/(x['vote_count']+m) * x['vote_average'])
+ (m/(m+x['vote_count']) * C), axis=1)
#Sort movies in descending order of their scores
q_movies = q_movies.sort_values('score', ascending=False)
return q_moviesWhen we execute this function we are asked the following 5 questions:
- Input preferred genre
- Input shortest duration
- Input longest duration
- Input earliest year
- Input latest year
Let’s try it out.
personal_recommendations = build_chart(gen_df).head(8)
personal_recommendations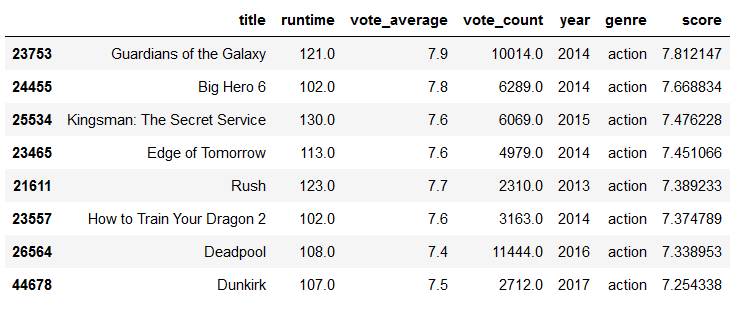
5 Conclusion
In this post I have shown how to prepare a data set (in this case one about movies) to create a simple knowldeged based recommender. In the following posts I will go deeper into the subject Recommendation Systems and show more complex methods.
References
The content of the entire post was created using the following sources:
Banik, R. (2018). Hands-On Recommendation Systems with Python: Start building powerful and personalized, recommendation engines with Python. Birmingham: Packt Publishing Ltd.