1 Introduction
In my last publication on “Grid Search” I showed how to do hyper parameter tuning. As you saw in the last chapter (6.3 Grid Search with more than one estimator), these calculations quickly become very computationally intensive. This sometimes leads to very long calculation times. Randomized Search is a cheap alternative to grid search. How Randomized Search work in detail I will show in this publication.
For this post the dataset Breast Cancer Wisconsin (Diagnostic) from the statistic platform “Kaggle” was used. You can download it from my GitHub Repository.
2 Grid Search vs. Randomized Search
First of all, let’s clarify the difference between Grid Search and Randomized Search.
Grid Search can be thought of as an exhaustive search for selecting a machine learning model. With Grid Search, the data scientist/analyst sets up a grid of hyperparameter values and for each combination, trains a model and scores on the testing data. In this approach, every combination of hyperparameter values is tried. This could be very inefficient and computationally intensive.
By contrast, Randomized Search sets up a grid of hyperparameter values and selects random combinations to train the model and score. This allows you to explicitly control the number of parameter combinations that are attempted. The number of search iterations is set based on time or resources. While it’s possible that Randomized Search will not find as accurate of a result as Grid Search, it surprisingly picks the best result more often than not and in a fraction of the time it takes Grid Search would have taken. Given the same resources, Randomized Search can even outperform Grid Search.
3 Loading the libraries and data
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import time
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import RandomizedSearchCVcancer = pd.read_csv("breast_cancer.csv")4 Data pre-processing
For this post I use the same data set and the same preparation as for “Grid Search”. I will therefore not go into much detail about the first steps. If you want to learn more about the respective pre-processing steps, please read my “Grid Search - Post”.
vals_to_replace = {'B':'0', 'M':'1'}
cancer['diagnosis'] = cancer['diagnosis'].map(vals_to_replace)
cancer['diagnosis'] = cancer.diagnosis.astype('int64')x = cancer.drop(['id', 'diagnosis', 'Unnamed: 32'], axis=1)
y = cancer['diagnosis']
trainX, testX, trainY, testY = train_test_split(x, y, test_size = 0.2)So let’s do our first prediction with a “Support Vector Machine”:
clf = SVC(kernel='linear')
clf.fit(trainX, trainY)
y_pred = clf.predict(testX)
print('Accuracy: {:.2f}'.format(accuracy_score(testY, y_pred)))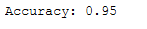
5 Grid Searach
Now we are going to do hyperparameter tuning with grid search. We also measure the time how long this tuning takes.
param_grid = {'C': [0.1, 1, 10, 100, 1000],
'gamma': [1, 0.1, 0.01, 0.001, 0.0001],
'kernel': ['linear']} start = time.time()
grid = GridSearchCV(SVC(), param_grid, cv = 5, scoring='accuracy')
grid.fit(trainX, trainY)
end = time.time()
print()
print('Calculation time: ' + str(round(end - start,2)) + ' seconds')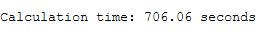
print(grid.best_params_) 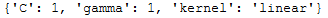
grid_predictions = grid.predict(testX)
print('Accuracy: {:.2f}'.format(accuracy_score(testY, grid_predictions)))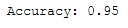
6 Randomized Search
Now we do the same hyperparameter tuning with Randomized Search.
param_rand_search = {'C': [0.1, 1, 10, 100, 1000],
'gamma': [1, 0.1, 0.01, 0.001, 0.0001],
'kernel': ['linear']}start = time.time()
rand_search = RandomizedSearchCV(SVC(), param_rand_search, cv = 5, scoring='accuracy')
rand_search.fit(trainX, trainY)
end = time.time()
print()
print('Calculation time: ' + str(round(end - start,2)) + ' seconds')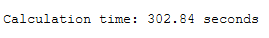
print(rand_search.best_params_) 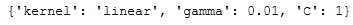
grand_search_predictions = rand_search.predict(testX)
print('Accuracy: {:.2f}'.format(accuracy_score(testY, grand_search_predictions)))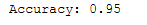
7 Conclusion
As we can see, Randomized Search took less than half the time it took to search with Grid Search. A different value was found for gamma, but the prediction accuracy remained the same (95%).