1 Introduction
Let’s continue in our post series about Text Pre-Processing.
In this post I will cover the following topics:
- POS
- NER and
- Normalization
For this publication the processed dataset Amazon Unlocked Mobile from the statistic platform “Kaggle” was used as well as the created Example String. You can download both files from my “GitHub Repository”.
2 Import the Libraries and the Data
import pandas as pd
import numpy as np
import pickle as pk
import warnings
warnings.filterwarnings("ignore")
from bs4 import BeautifulSoup
import unicodedata
import re
from nltk.tokenize import word_tokenize
from nltk.tokenize import sent_tokenize
from nltk.corpus import stopwords
from nltk.corpus import wordnet
from nltk import pos_tag
from nltk import ne_chunk
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.probability import FreqDist
import matplotlib.pyplot as plt
from wordcloud import WordCloudpd.set_option('display.max_colwidth', 30)df = pd.read_csv('Amazon_Unlocked_Mobile_small_Part_II.csv')
df.head()
df['Reviews_wo_Stop_Words'] = df['Reviews_wo_Stop_Words'].astype(str)clean_text_wo_stop_words = pk.load(open("clean_text_wo_stop_words.pkl",'rb'))
clean_text_wo_stop_words
3 Definition of required Functions
All functions are summarized here. I will show them again where they are used during this post if they are new and have not been explained yet.
def word_count_func(text):
'''
Counts words within a string
Args:
text (str): String to which the function is to be applied, string
Returns:
Number of words within a string, integer
'''
return len(text.split())def norm_stemming_func(text):
'''
Stemming tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use PorterStemmer() to stem the created tokens
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with stemmed words
'''
words = word_tokenize(text)
text = ' '.join([PorterStemmer().stem(word) for word in words])
return textdef norm_lemm_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() to lemmatize the created tokens
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words = word_tokenize(text)
text = ' '.join([WordNetLemmatizer().lemmatize(word) for word in words])
return textdef norm_lemm_v_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() to lemmatize the created tokens
POS tag is set to 'v' for verb
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words = word_tokenize(text)
text = ' '.join([WordNetLemmatizer().lemmatize(word, pos='v') for word in words])
return textdef norm_lemm_a_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() to lemmatize the created tokens
POS tag is set to 'a' for adjective
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words = word_tokenize(text)
text = ' '.join([WordNetLemmatizer().lemmatize(word, pos='a') for word in words])
return textdef get_wordnet_pos_func(word):
'''
Maps the respective POS tag of a word to the format accepted by the lemmatizer of wordnet
Args:
word (str): Word to which the function is to be applied, string
Returns:
POS tag, readable for the lemmatizer of wordnet
'''
tag = pos_tag([word])[0][1][0].upper()
tag_dict = {"J": wordnet.ADJ,
"N": wordnet.NOUN,
"V": wordnet.VERB,
"R": wordnet.ADV}
return tag_dict.get(tag, wordnet.NOUN)def norm_lemm_POS_tag_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() to lemmatize the created tokens
POS tag is determined with the help of function get_wordnet_pos()
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words = word_tokenize(text)
text = ' '.join([WordNetLemmatizer().lemmatize(word, get_wordnet_pos_func(word)) for word in words])
return textdef norm_lemm_v_a_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() with POS tag 'v' to lemmatize the created tokens
Step 3: Use word_tokenize() to get tokens from generated string
Step 4: Use WordNetLemmatizer() with POS tag 'a' to lemmatize the created tokens
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words1 = word_tokenize(text)
text1 = ' '.join([WordNetLemmatizer().lemmatize(word, pos='v') for word in words1])
words2 = word_tokenize(text1)
text2 = ' '.join([WordNetLemmatizer().lemmatize(word, pos='a') for word in words2])
return text24 Text Pre-Processing
4.1 (Text Cleaning)
I have already described this part in an earlier post. See here: Text Cleaning
4.2 (Tokenization)
I have already described this part in the previous post. See here: Text Pre-Processing II-Tokenization
4.3 (Stop Words)
I have already described this part in the previous post. See here: Text Pre-Processing II-Stop Words
4.4 Digression: POS & NER
In the following I will briefly explain what Part of Speech Tagging (POS) and Named Entity Recognition (NER) is and what we will need it for in the context of text pre-processing.
pos_ner_text = "Bill Gates founded Microsoft Corp. together with Paul Allen in 1975."
pos_ner_text
4.4.1 Part of Speech Tagging (POS)
Part-of-speech tagging (POS tagging) aims to identify which grammatical group a word belongs to, i.e. whether it is a noun, adjective, verb, adverb, etc., based on the context.
Relationships within the sentence are searched for and each word in a sentence is tagged with the appropriate tag.
Here is a list of Part of Speech tags.
POS_tag = pos_tag(word_tokenize(pos_ner_text))
POS_tag
As we can see, Bill Gates and Paul Allen are correctly recognized as NNP (Proper noun, singular) and tagged accordingly. The same applies to Microsoft. Now let’s see what comes out of NER.
4.4.2 Named Entity Recognition (NER)
Named Entity Recognition (NER) tries to find out whether a word is a named entity or not. Named entities are places, organisations, people, time expressions, etc.
POS is more of a global problem, as there can be relationships between the first and last word of a sentence.
In contrast, NER is more of a local problem, since named entities are not distributed in a sentence and mostly consist of uni-, bi- or trigrams.
NER_tree = ne_chunk(pos_tag(word_tokenize(pos_ner_text)))
print(NER_tree)
Again, Bill Gates and Paul Allen are recognised as NNP. In addition, however, we still receive the information here that they are (correctly) persons. If we look at Microsoft, we see that it was not only tagged as an NNP but also recognised as an organisation.
But what do we need all this for in our project?
There are many other things you can do with POS and NER and I will explain these two topics in more detail in separate posts, but for now it is sufficient to know what these two methods basically do.
The following chapter will be about normalising texts. The aim here is to bring the words into their basic form in order to make them even more meaningful for further analysis. The algorithms used for this partly use POS and NER, so it is useful to know roughly what is happening here.
4.5 Normalization
Text normalisation tries to reduce the randomness in text and bring it closer to a predefined standard. This has the effect of reducing the amount of different information (that the further algorithms have to work with) and thus improving efficiency.
There are two methods for this:
- Stemming and
- Lemmatization
The aim of these normalisation techniques is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form.
Stemming is the process of reducing words to their root or root form. Here, stemming algorithms work by cutting off the beginning or end of a word, taking into account a list of common prefixes and suffixes. However, this random cutting does not always work. Therefore, this approach has some limitations.
In lemmatization, words are reduced to their base word. The lemmatization algorithms try to reduce the inflected words correctly so that the affiliation of the base word to the language is guaranteed.
The difference between stemming and lemmatization is that a stemming algorithm works with a single word without knowing the context of the whole sentence and therefore cannot distinguish between words that have different meanings depending on the type of word. One advantage of stemming algorithms is that they are easier to implement and run faster. If accuracy is not so important for the application, stemming algorithms are the right choice. What increases the working time of lemmatization algorithms is that the part of speech of a word has to be determined first and in this process the normalisation rules will be different for different parts of speech.
stemmer = PorterStemmer()
lemmatizer = WordNetLemmatizer()
print("Original Word: 'studies' ")
print()
print('With Stemming: ' + str(stemmer.stem("studies")))
print('with Lemmatization: ' + str(lemmatizer.lemmatize("studies")))
text_for_normalization = "\
I saw an amazing thing and ran. \
It took too long. \
We are eating and swimming. \
I want better dog.\
"
text_for_normalization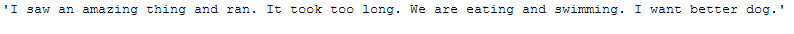
4.5.1 Stemming
PorterStemmer (which we will also use in the following for this task) is probably the best known stemming algorithm.
But there are several others that can be used:
def norm_stemming_func(text):
'''
Stemming tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use PorterStemmer() to stem the created tokens
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with stemmed words
'''
words = word_tokenize(text)
text = ' '.join([PorterStemmer().stem(word) for word in words])
return textnorm_stemming_func(text_for_normalization)
4.5.2 Lemmatization
As with stemming, there are several algorithms that can be used for lemmatization:
We use the WordNetLemmatizer from nltk for the following examples.
def norm_lemm_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() to lemmatize the created tokens
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words = word_tokenize(text)
text = ' '.join([WordNetLemmatizer().lemmatize(word) for word in words])
return textnorm_lemm_func(text_for_normalization)
Notice the WordNetLemmatizer function didn’t do a good job. Because, ‘are’ is not converted to ‘be’ and ‘swimming’ is not converted to ‘swim’ as expected.
4.5.2.1 Wordnet Lemmatizer with specific POS tag
With the Wordnet Lemmatizer you have the possibility to set a specific POS tag. Let’s set this to pos=‘v’ where ‘v’ stands for ‘verb’. Usually this POS tag is used.
def norm_lemm_v_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() to lemmatize the created tokens
POS tag is set to 'v' for verb
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words = word_tokenize(text)
text = ' '.join([WordNetLemmatizer().lemmatize(word, pos='v') for word in words])
return textnorm_lemm_v_func(text_for_normalization)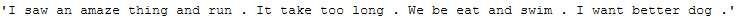
Perfect, now it’s almost the way we want it (‘are’ became ‘be’ and ‘eating’ and ‘swimming’ became ‘eat’ and ‘swim’). One exception is ‘saw’. One would have expected that this word would be changed to ‘see’. Why this is a strange exception can be read here.
Let’s take a look at the phrase ‘I want better dog’. Instead of ‘better’ I would like to have ‘good’ or ‘well’. But since this is not a verb but an adjective we would have to use the WordNetLemmatizer with the POS tag = ‘a’ for adjective. Also for this I wrote a function that does exactly that:
def norm_lemm_a_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() to lemmatize the created tokens
POS tag is set to 'a' for adjective
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words = word_tokenize(text)
text = ' '.join([WordNetLemmatizer().lemmatize(word, pos='a') for word in words])
return textnorm_lemm_a_func(text_for_normalization)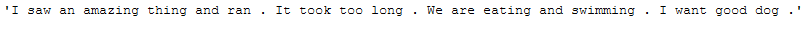
Has worked but unfortunately now again the verbs were not taken into account.
For this problem there are two ways which I would like to introduce in the following two chapters.
4.5.2.2 Wordnet Lemmatizer with appropriate POS tag
One possibility would be to write a function that determines the respective POS tag of a word and passes it to the lemmatization function for the respective token.
Here are the Part-of-speech constants:
- ADJ = ‘a’
- ADJ_SAT = ‘s’
- ADV = ‘r’
- NOUN = ‘n’
- VERB = ‘v’
def get_wordnet_pos_func(word):
'''
Maps the respective POS tag of a word to the format accepted by the lemmatizer of wordnet
Args:
word (str): Word to which the function is to be applied, string
Returns:
POS tag, readable for the lemmatizer of wordnet
'''
tag = pos_tag([word])[0][1][0].upper()
tag_dict = {"J": wordnet.ADJ,
"N": wordnet.NOUN,
"V": wordnet.VERB,
"R": wordnet.ADV}
return tag_dict.get(tag, wordnet.NOUN)def norm_lemm_POS_tag_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() to lemmatize the created tokens
POS tag is determined with the help of function get_wordnet_pos()
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words = word_tokenize(text)
text = ' '.join([WordNetLemmatizer().lemmatize(word, get_wordnet_pos_func(word)) for word in words])
return textprint('POS tag for the word "dog": ' + str(get_wordnet_pos_func("dog")))
print('POS tag for the word "going": ' + str(get_wordnet_pos_func("going")))
print('POS tag for the word "good": ' + str(get_wordnet_pos_func("good")))
norm_lemm_POS_tag_func(text_for_normalization)
4.5.2.3 Multiple specific Wordnet Lemmatizer
Another alternative is to run two lemmatization algorithms with different specific POS tags one after the other:
text_for_norm_v_lemmatized = norm_lemm_v_func(text_for_normalization)
text_for_norm_n_lemmatized = norm_lemm_a_func(text_for_norm_v_lemmatized)
text_for_norm_n_lemmatized
Personally, I find it easier to write this back into a function:
def norm_lemm_v_a_func(text):
'''
Lemmatize tokens from string
Step 1: Use word_tokenize() to get tokens from string
Step 2: Use WordNetLemmatizer() with POS tag 'v' to lemmatize the created tokens
Step 3: Use word_tokenize() to get tokens from generated string
Step 4: Use WordNetLemmatizer() with POS tag 'a' to lemmatize the created tokens
Args:
text (str): String to which the functions are to be applied, string
Returns:
String with lemmatized words
'''
words1 = word_tokenize(text)
text1 = ' '.join([WordNetLemmatizer().lemmatize(word, pos='v') for word in words1])
words2 = word_tokenize(text1)
text2 = ' '.join([WordNetLemmatizer().lemmatize(word, pos='a') for word in words2])
return text2norm_lemm_v_a_func(text_for_normalization)
4.5.3 Application to the Example String
clean_text_wo_stop_words
with norm_lemm_v_a_func
clean_text_lemmatized_v_a = norm_lemm_v_a_func(clean_text_wo_stop_words)
clean_text_lemmatized_v_a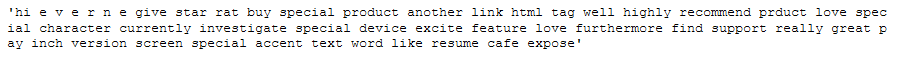
with norm_lemm_POS_tag_func
clean_text_lemmatized_pos_tag = norm_lemm_POS_tag_func(clean_text_wo_stop_words)
clean_text_lemmatized_pos_tag
This example shows the advantages and disadvantages of the two variants. With the v_a_func, ‘bought’ became ‘buy’ and ‘paid’ became ‘pay’. On the other hand, ‘rating’ became ‘rat’.
With the pos_tag function, on the other hand, the past tense remained, but ‘rating’ was not reformatted to the word rat.
This is the well-known No Free Lunch Theorem where we have to weigh up which variant with which advantages and disadvantages we want to take.
In this post series I will continue to work with the norm_lemm_v_a function for the Example String and the DataFrame.
4.5.4 Application to the DataFrame
df.head(3).T
df['Reviews_lemmatized'] = df['Reviews_wo_Stop_Words'].apply(norm_lemm_v_a_func)
df['Word_Count_lemmatized_Reviews'] = df['Reviews_lemmatized'].apply(word_count_func)
df.head(3).T
5 Conclusion
In this part of the Text Pre-Processing series, I have given a brief example explanation of what POS and NER are and what these two techniques are to be used for.
Furthermore, I went into detail about normalization techniques for text data.
I save the edited DataFrame and Example String again for subsequent use.
pk.dump(clean_text_lemmatized_v_a, open('clean_text_lemmatized_v_a.pkl', 'wb'))
df.to_csv('Amazon_Unlocked_Mobile_small_Part_III.csv', index = False)