1 Introduction
In my last publication, I started the post series on the topic of text pre-processing. In it, I first covered all the possible applications of Text Cleaning.
Now I will continue with the topics Tokenization and Stop Words.
For this publication the processed dataset Amazon Unlocked Mobile from the statistic platform “Kaggle” was used as well as the created Example String. You can download both files from my “GitHub Repository”.
2 Import the Libraries and the Data
import pandas as pd
import numpy as np
import pickle as pk
import warnings
warnings.filterwarnings("ignore")
from bs4 import BeautifulSoup
import unicodedata
import re
from nltk.tokenize import word_tokenize
from nltk.tokenize import sent_tokenize
from nltk.corpus import stopwords
from nltk.corpus import wordnet
from nltk import pos_tag
from nltk import ne_chunk
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.probability import FreqDist
import matplotlib.pyplot as plt
from wordcloud import WordClouddf = pd.read_csv('Amazon_Unlocked_Mobile_small_Part_I.csv')
df.head()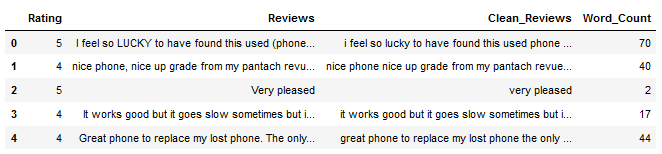
df['Clean_Reviews'] = df['Clean_Reviews'].astype(str)clean_text = pk.load(open("clean_text.pkl",'rb'))
clean_text
3 Definition of required Functions
All functions are summarized here. I will show them again where they are used during this post if they are new and have not been explained yet.
def word_count_func(text):
'''
Counts words within a string
Args:
text (str): String to which the function is to be applied, string
Returns:
Number of words within a string, integer
'''
return len(text.split())def remove_english_stopwords_func(text):
'''
Removes Stop Words (also capitalized) from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without Stop Words
'''
# check in lowercase
t = [token for token in text if token.lower() not in stopwords.words("english")]
text = ' '.join(t)
return text4 Text Pre-Processing
4.1 (Text Cleaning)
I have already described this part in the previous post. See here: Text Cleaning
4.2 Tokenization
Tokenisation is a technique for breaking down a piece of text into small units, called tokens. A token may be a word, part of a word or just characters like punctuation.
Tokenisation can therefore be roughly divided into three groups:
- Word Tokenization
- Character Tokenization and
- Partial Word Tokenization (n-gram characters)
In the following I will present two tokenizers:
- Word Tokenizer
- Sentence Tokenizer
Of course there are some more. Find the one on the NLTK Homepage which fits best to your data or to your problem solution.
text_for_tokenization = \
"Hi my name is Michael. \
I am an enthusiastic Data Scientist. \
Currently I am working on a post about NLP, more specifically about the Pre-Processing Steps."
text_for_tokenization
4.2.1 Word Tokenizer
To break a sentence into words, the word_tokenize() function can be used. Based on this, further text cleaning steps can be taken such as removing stop words or normalising text blocks. In addition, machine learning models need numerical data to be trained and make predictions. Again, tokenisation of words is a crucial part of converting text into numerical data.
words = word_tokenize(text_for_tokenization)
print(words)
print('Number of tokens found: ' + str(len(words)))
4.2.2 Sentence Tokenizer
Now the question arises, why do I actually need to tokenise sentences when I can tokenise individual words?
An example of use would be if you want to count the average number of words per sentence. How can I do that with the Word Tokenizer alone? I can’t, I need both the sent_tokenize() function and the word_tokenize() function to calculate the ratio.
sentences = sent_tokenize(text_for_tokenization)
print(sentences)
print('Number of sentences found: ' + str(len(sentences)))
for each_sentence in sentences:
n_words=word_tokenize(each_sentence)
print(each_sentence) 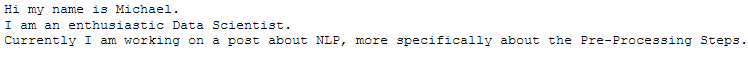
for each_sentence in sentences:
n_words=word_tokenize(each_sentence)
print(len(n_words))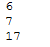
4.2.3 Application to the Example String
tokens_clean_text = word_tokenize(clean_text)
print(tokens_clean_text)
print('Number of tokens found: ' + str(len(tokens_clean_text)))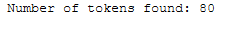
4.2.4 Application to the DataFrame
df.head()
Here I set a limit for the column width so that it remains clear. This setting should be reset at the end, otherwise it will remain.
pd.set_option('display.max_colwidth', 30)df['Reviews_Tokenized'] = df['Clean_Reviews'].apply(word_tokenize)
df.head()
df['Token_Count'] = df['Reviews_Tokenized'].str.len()
df.head()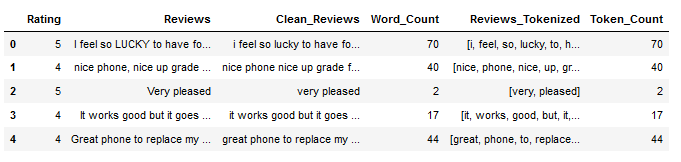
It is always worthwhile (I have made a habit of doing this) to have the number of remaining words or tokens displayed and also to store them in the data record. The advantage of this is that (especially in later process steps) it is very quick and easy to see what influence the operation has had on the quality of my information. Of course, this can only be done on a random basis, but it is easy to see whether the function applied had negative effects that were not intended. Or you look at a case difference if you don’t know which type of algorithm (for example, in normalisation) fits my data better.
print('Average of words counted: ' + str(df['Word_Count'].mean()))
print('Average of tokens counted: ' + str(df['Token_Count'].mean()))
Ok interesting, the average number of words has increased slightly. Let’s take a look at what caused that:
df_subset = df[['Clean_Reviews', 'Word_Count', 'Reviews_Tokenized', 'Token_Count']]
df_subset['Diff'] = df_subset['Token_Count'] - df_subset['Word_Count']
df_subset = df_subset[(df_subset["Diff"] != 0)]
df_subset.sort_values(by='Diff', ascending=False)
Note: In the following I do not take the first row from the sorted dataset, but from the created dataset df_subset.
df_subset['Clean_Reviews'].iloc[0]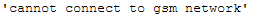
df_subset['Reviews_Tokenized'].iloc[0]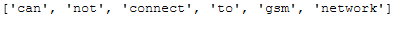
Here we see the reason: The tokenizer has turned ‘cannot’ into ‘can not’.
4.3 Stop Words
Stop words are frequently used words such as I, a, an, in etc. They do not contribute significantly to the information content of a sentence, so it is advisable to remove them by storing a list of words that we consider stop words. The library nltk has such lists for 16 different languages that we can refer to.
Here are the defined stop words for the English language:
print(stopwords.words("english"))
text_for_stop_words = "Hi my name is Michael. I am an enthusiastic Data Scientist."
text_for_stop_words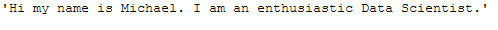
Stop Words can be removed well with the following function. However, the sentences must be converted into word tokens for this. I have explained in detail how to do this in the previous chapter.
tokens_text_for_stop_words = word_tokenize(text_for_stop_words)
print(tokens_text_for_stop_words)
def remove_english_stopwords_func(text):
'''
Removes Stop Words (also capitalized) from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without Stop Words
'''
# check in lowercase
t = [token for token in text if token.lower() not in stopwords.words("english")]
text = ' '.join(t)
return textremove_english_stopwords_func(tokens_text_for_stop_words)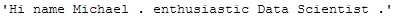
4.3.1 Application to the Example String
print(tokens_clean_text)
print('Number of tokens found: ' + str(len(tokens_clean_text)))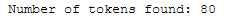
stop_words_within_tokens_clean_text = [w for w in tokens_clean_text if w in stopwords.words("english")]
print()
print('These Stop Words were found in our example string:')
print()
print(stop_words_within_tokens_clean_text)
print()
print('Number of Stop Words found: ' + str(len(stop_words_within_tokens_clean_text)))
clean_text_wo_stop_words = [w for w in tokens_clean_text if w not in stopwords.words("english")]
print()
print('These words would remain after Stop Words removal:')
print()
print(clean_text_wo_stop_words)
print()
print('Number of remaining words: ' + str(len(clean_text_wo_stop_words)))
clean_text_wo_stop_words = remove_english_stopwords_func(tokens_clean_text)
clean_text_wo_stop_words
Note: After removing the stop words we need the word_count function again for counting, because they are no tokens anymore.
print('Number of words: ' + str(word_count_func(clean_text_wo_stop_words)))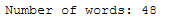
4.3.2 Application to the DataFrame
df.head()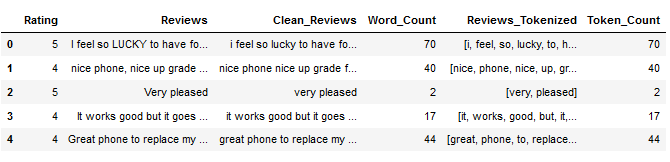
df['Reviews_wo_Stop_Words'] = df['Reviews_Tokenized'].apply(remove_english_stopwords_func)
df.head()
df['Word_Count_wo_Stop_Words'] = df['Reviews_wo_Stop_Words'].apply(word_count_func)
df.head().T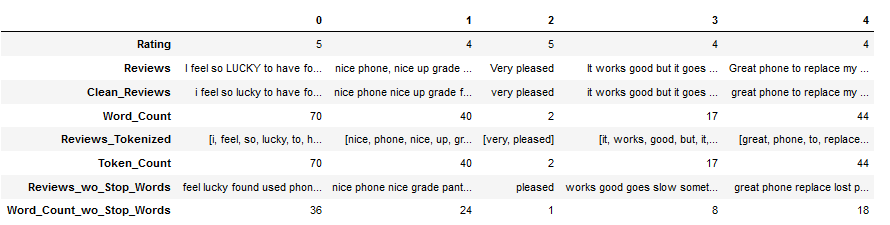
5 Conclusion
In this part of the Text Pre-Processing series, I explained how tokenization works, how to use it, and showed how to remove Stop Words.
I save the edited DataFrame and Example String again for subsequent use.
pk.dump(clean_text_wo_stop_words, open('clean_text_wo_stop_words.pkl', 'wb'))
df.to_csv('Amazon_Unlocked_Mobile_small_Part_II.csv', index = False)