- 1 Introduction
- 2 Import the Libraries and the Data
- 3 Definition of required Functions
- 4 Text Pre-Processing
- 4.1 Text Cleaning
- 4.1.1 Conversion to Lower Case
- 4.1.2 Removing HTML-Tags
- 4.1.3 Removing URLs
- 4.1.4 Removing Accented Characters
- 4.1.5 Removing Punctuation
- 4.1.6 Removing irrelevant Characters (Numbers and Punctuation)
- 4.1.7 Removing extra Whitespaces
- 4.1.8 Extra: Count Words
- 4.1.9 Extra: Expanding Contractions
- 4.1.10 Application to the Example String
- 4.1.11 Application to the DataFrame
- 4.1 Text Cleaning
- 5 Conclusion
1 Introduction
In my last post (NLP - Text Manipulation) I got into the topic of Natural Language Processing.
However, before we can start with Machine Learning algorithms some preprocessing steps are needed. I will introduce these in this and the following posts. Since this is a coherent post series and will build on each other I recommend to start with reading this post.
For this publication the dataset Amazon Unlocked Mobile from the statistic platform “Kaggle” was used. You can download it from my “GitHub Repository”.
2 Import the Libraries and the Data
If you are using the nltk library for the first time, you should import and download the following:
import nltk
nltk.download('punkt')
nltk.download('stopwords')
nltk.download('wordnet')
nltk.download('averaged_perceptron_tagger')
nltk.download('maxent_ne_chunker')import pandas as pd
import numpy as np
import pickle as pk
import warnings
warnings.filterwarnings("ignore")
from bs4 import BeautifulSoup
import unicodedata
import re
from nltk.tokenize import word_tokenize
from nltk.tokenize import sent_tokenize
from nltk.corpus import stopwords
from nltk.corpus import wordnet
from nltk import pos_tag
from nltk import ne_chunk
from nltk.stem.porter import PorterStemmer
from nltk.stem.wordnet import WordNetLemmatizer
from nltk.probability import FreqDist
import matplotlib.pyplot as plt
from wordcloud import WordClouddf = pd.read_csv('Amazon_Unlocked_Mobile_small.csv')
df.head()
However, we will only work with the following part of the data set:
df = df[['Rating', 'Reviews']]
df.head()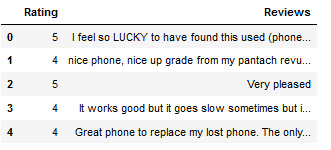
Let’s take a closer look at the first set of reviews:
df['Reviews'].iloc[0]
df.dtypes
To be on the safe side, I convert the reviews as strings to be able to work with them correctly.
df['Reviews'] = df['Reviews'].astype(str)3 Definition of required Functions
All functions are summarized here. I will show them again in the course of this post at the place where they are used.
def remove_html_tags_func(text):
'''
Removes HTML-Tags from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without HTML-Tags
'''
return BeautifulSoup(text, 'html.parser').get_text()def remove_url_func(text):
'''
Removes URL addresses from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without URL addresses
'''
return re.sub(r'https?://\S+|www\.\S+', '', text)def remove_accented_chars_func(text):
'''
Removes all accented characters from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without accented characters
'''
return unicodedata.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8', 'ignore')def remove_punctuation_func(text):
'''
Removes all punctuation from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without punctuations
'''
return re.sub(r'[^a-zA-Z0-9]', ' ', text)def remove_irr_char_func(text):
'''
Removes all irrelevant characters (numbers and punctuation) from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without irrelevant characters
'''
return re.sub(r'[^a-zA-Z]', ' ', text)def remove_extra_whitespaces_func(text):
'''
Removes extra whitespaces from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without extra whitespaces
'''
return re.sub(r'^\s*|\s\s*', ' ', text).strip()def word_count_func(text):
'''
Counts words within a string
Args:
text (str): String to which the function is to be applied, string
Returns:
Number of words within a string, integer
'''
return len(text.split())4 Text Pre-Processing
There are some text pre-processing steps to consider and a few more you can do. In this post I will talk about text cleaning.
4.1 Text Cleaning
Here I have created an example string, where you can understand the following steps very well.
messy_text = \
"Hi e-v-e-r-y-o-n-e !!!@@@!!! I gave a 5-star rating. \
Bought this special product here: https://www.amazon.com/. Another link: www.amazon.com/ \
Here the HTML-Tag as well: <a href='https://www.amazon.com/'> …</a>. \
I HIGHLY RECOMMEND THIS PRDUCT !! \
I @ (love) [it] <for> {all} ~it's* |/ #special / ^^characters;! \
I am currently investigating the special device and am excited about the features. Love it! \
Furthermore, I found the support really great. Paid about 180$ for it (5.7inch version, 4.8'' screen). \
Sómě special Áccěntěd těxt and words like résumé, café or exposé.\
"
messy_text
In the following I will perform the individual steps for text cleaning and always use parts of the messy_text string.
4.1.1 Conversion to Lower Case
In general, it is advisable to format the text completely in lower case.
messy_text_lower_case = \
"I HIGHLY RECOMMEND THIS PRDUCT !!\
"
messy_text_lower_case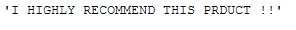
messy_text_lower_case.lower()
4.1.2 Removing HTML-Tags
messy_text_html = \
"Here the HTML-Tag as well: <a href='https://www.amazon.com/'> …</a>.\
"
messy_text_html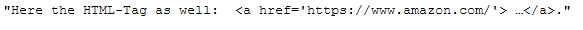
def remove_html_tags_func(text):
'''
Removes HTML-Tags from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without HTML-Tags
'''
return BeautifulSoup(text, 'html.parser').get_text()remove_html_tags_func(messy_text_html)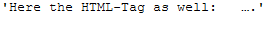
4.1.3 Removing URLs
messy_text_url = \
"Bought this product here: https://www.amazon.com/. Another link: www.amazon.com/\
"
messy_text_url
def remove_url_func(text):
'''
Removes URL addresses from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without URL addresses
'''
return re.sub(r'https?://\S+|www\.\S+', '', text)remove_url_func(messy_text_url)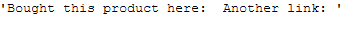
4.1.4 Removing Accented Characters
messy_text_accented_chars = \
"Sómě Áccěntěd těxt and words like résumé, café or exposé.\
"
messy_text_accented_chars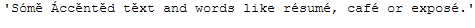
def remove_accented_chars_func(text):
'''
Removes all accented characters from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without accented characters
'''
return unicodedata.normalize('NFKD', text).encode('ascii', 'ignore').decode('utf-8', 'ignore')remove_accented_chars_func(messy_text_accented_chars)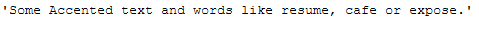
4.1.5 Removing Punctuation
Punctuation is essentially the following set of symbols: [!”#$%&’()*+,-./:;<=>?@[]^_`{|}~]
messy_text_remove_punctuation = \
"Furthermore, I found the support really great. Paid about 180$ for it (5.7inch version, 4.8'' screen).\
"
messy_text_remove_punctuation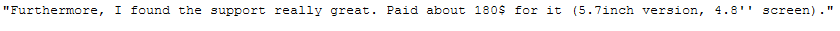
def remove_punctuation_func(text):
'''
Removes all punctuation from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without punctuations
'''
return re.sub(r'[^a-zA-Z0-9]', ' ', text)remove_punctuation_func(messy_text_remove_punctuation)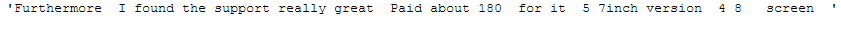
4.1.6 Removing irrelevant Characters (Numbers and Punctuation)
messy_text_irr_char = \
"Furthermore, I found the support really great. Paid about 180$ for it (5.7inch version, 4.8'' screen).\
"
messy_text_irr_char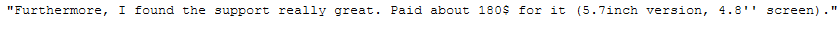
I am aware that this is the same example sentence as in the previous example, but here the difference between this and the previous function is made clear.
def remove_irr_char_func(text):
'''
Removes all irrelevant characters (numbers and punctuation) from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without irrelevant characters
'''
return re.sub(r'[^a-zA-Z]', ' ', text)remove_irr_char_func(messy_text_irr_char)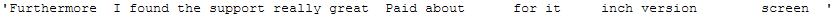
4.1.7 Removing extra Whitespaces
messy_text_extra_whitespaces = \
"I am a text with many whitespaces.\
"
messy_text_extra_whitespaces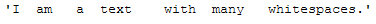
def remove_extra_whitespaces_func(text):
'''
Removes extra whitespaces from a string, if present
Args:
text (str): String to which the function is to be applied, string
Returns:
Clean string without extra whitespaces
'''
return re.sub(r'^\s*|\s\s*', ' ', text).strip()remove_extra_whitespaces_func(messy_text_extra_whitespaces)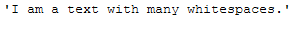
I always like to use this function in between, for example, when you have removed stop words, certain words or individual characters from the string(s). From time to time, this creates new whitespaces that I always like to remove for the sake of order.
4.1.8 Extra: Count Words
It is worthwhile to display the number of existing words, especially for validation of the pre-proessing steps. We will use this function again and again in later steps.
messy_text_word_count = \
"How many words do you think I will contain?\
"
messy_text_word_count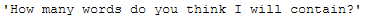
def word_count_func(text):
'''
Counts words within a string
Args:
text (str): String to which the function is to be applied, string
Returns:
Number of words within a string, integer
'''
return len(text.split())word_count_func(messy_text_word_count)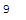
4.1.9 Extra: Expanding Contractions
You can do expanding contractions but you don’t have to. For the sake of completeness, I list the necessary functions, but do not use them in our following example with the Example String and DataFrame. I will give the reason for this in a later chapter.
from contractions import CONTRACTION_MAP
import re
def expand_contractions(text, map=CONTRACTION_MAP):
pattern = re.compile('({})'.format('|'.join(map.keys())), flags=re.IGNORECASE|re.DOTALL)
def get_match(contraction):
match = contraction.group(0)
first_char = match[0]
expanded = map.get(match) if map.get(match) else map.get(match.lower())
expanded = first_char+expanded[1:]
return expanded
new_text = pattern.sub(get_match, text)
new_text = re.sub("'", "", new_text)
return new_textWith the help of this function, this sentence:

becomes the following:
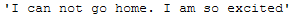
This function should also work for this:
from pycontractions import Contractions
cont = Contractions(kv_model=model)
cont.load_models()#
def expand_contractions(text):
text = list(cont.expand_texts([text], precise=True))[0]
return text4.1.10 Application to the Example String
Before that, I used individual text modules to show how all the text cleaning steps work. Now it is time to apply these functions to Example String (and subsequently to the DataFrame) one after the other.
messy_text
messy_text_lower = messy_text.lower()
messy_text_lower
messy_text_wo_html = remove_html_tags_func(messy_text_lower)
messy_text_wo_html
messy_text_wo_url = remove_url_func(messy_text_wo_html)
messy_text_wo_url
messy_text_wo_acc_chars = remove_accented_chars_func(messy_text_wo_url)
messy_text_wo_acc_chars
messy_text_wo_punct = remove_punctuation_func(messy_text_wo_acc_chars)
messy_text_wo_punct
messy_text_wo_irr_char = remove_irr_char_func(messy_text_wo_punct)
messy_text_wo_irr_char
clean_text = remove_extra_whitespaces_func(messy_text_wo_irr_char)
clean_text
print('Number of words: ' + str(word_count_func(clean_text)))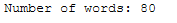
4.1.11 Application to the DataFrame
Now we apply the Text Cleaning Steps shown above to the DataFrame:
df.head()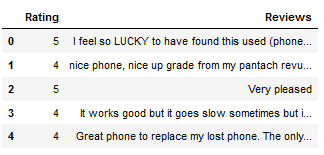
df['Clean_Reviews'] = df['Reviews'].str.lower()
df['Clean_Reviews'] = df['Clean_Reviews'].apply(remove_html_tags_func)
df['Clean_Reviews'] = df['Clean_Reviews'].apply(remove_url_func)
df['Clean_Reviews'] = df['Clean_Reviews'].apply(remove_accented_chars_func)
df['Clean_Reviews'] = df['Clean_Reviews'].apply(remove_punctuation_func)
df['Clean_Reviews'] = df['Clean_Reviews'].apply(remove_irr_char_func)
df['Clean_Reviews'] = df['Clean_Reviews'].apply(remove_extra_whitespaces_func)
df.head()
Let’s now compare the sentences from line 1 with the ones we have now edited:
df['Reviews'].iloc[0]
df['Clean_Reviews'].iloc[0]
Finally, we output the number of words and store them in a separate column. In this way, we can see whether and to what extent the number of words has changed in further steps.
df['Word_Count'] = df['Clean_Reviews'].apply(word_count_func)
df[['Clean_Reviews', 'Word_Count']].head()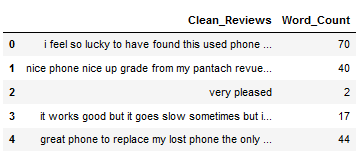
Here is the average number of words:
print('Average of words counted: ' + str(df['Word_Count'].mean()))
5 Conclusion
This was the first post in my series about text pre-processing. In it I have listed all the necessary steps that should always be followed (except in exceptional cases).
To be able to proceed with the edited record in the next post, I save it and the Example String.
pk.dump(clean_text, open('clean_text.pkl', 'wb'))
df.to_csv('Amazon_Unlocked_Mobile_small_Part_I.csv', index = False)In the following post I will link where you can find these two files. Stay tuned to learn more about Text Pre-Processing.