A Udacity Data Science Nanodegree Capstone Project to classify Dog-Breeds using a pre-trained CNN Model.

Introduction
The purpose of this project is to use a convolutional neural network (CNN) to predict dog breeds. I created a pipeline that can be used in a web or mobile app to process real images taken by users. Based on a picture of a dog, the algorithm I created can make an assessment about the dog breed. If supplied an image of a human, the code will identify the resembling dog breed.
If a dog is recognised in the image supplied, the algorithm returns the corresponding breed:


If a human is recognised in the image provided, the algorithm returns the resembling dog breed:

The use of deep learning technology has advanced the world of artificial intelligence. With this technology, computers are enabled to see, hear and speak. Trained on a matched data set in sufficient quantity, the performance of these AI solutions now surpasses humans. Using TensorFlow and Keras, it is very easy to create models whose performance is acceptable with a manageable amount of work and also a small amount of data.
In the following, I will explain how I proceeded and what results the developed neural networks gave me.
Data Exploration & Visualizations
I was provided with two data sets by Udacity:
The humans dataset contained 13,233 images of human faces which I detected with OpenCV’s implementation of Haar feature-based cascade classifiers.

The convolutional neural network (CNN) model was trained on the dog dataset that contains 133 dog breed categories and 8,351 images. Of these, 6,680 images were used for training, 835 for validation and 836 for testing.
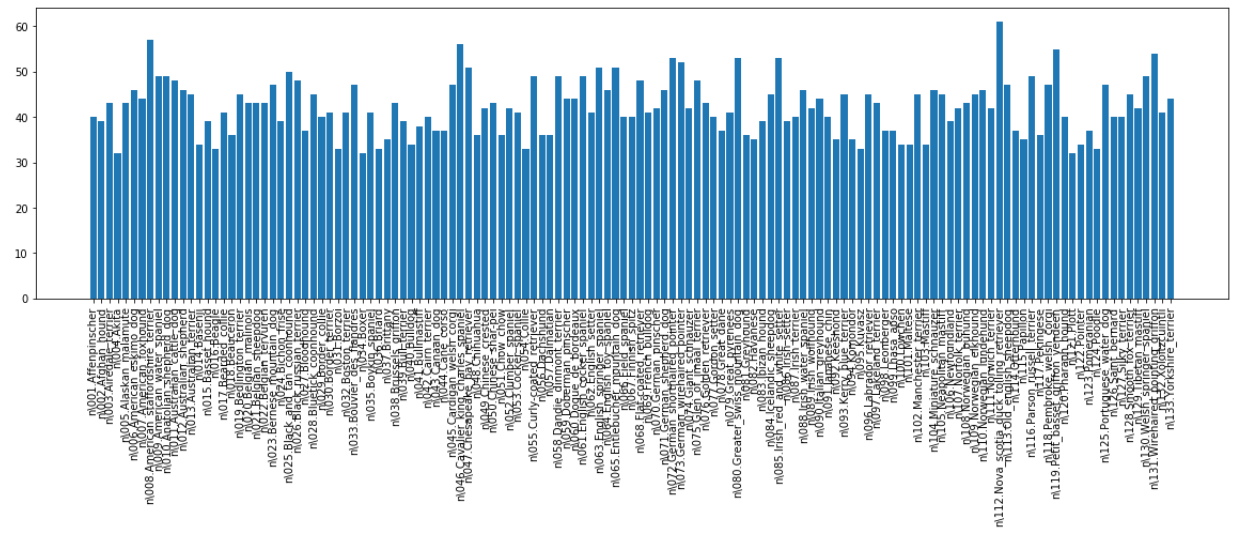
From the chart shown, we can see that the dog classes represented (approximately 50 per each category) are balanced, so we can use accuaracy as our evaluation metric. Here are a few sample pictures from the dogs dataset:



The dog pictures provided have different sizes and different orientations. This is shown in the visualisations below.
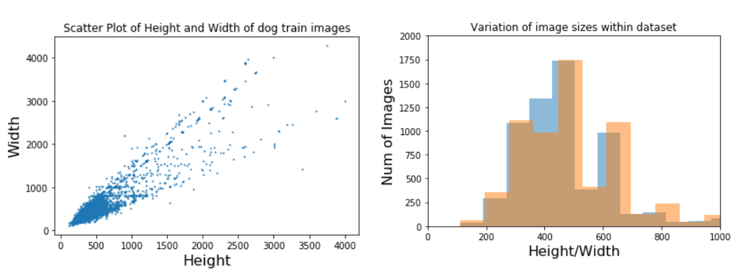
Due to this, the images were reduced to 224x224 pixels as part of the pre-processing step to fit the network architecture.
Identification of humans or dogs
As mentioned at the beginning, I used Haar feature-based cascade classifiers to identify whether the image contained a human face or not. I tested this detector on the first 100 images from the human and dog datasets. It achieved 99% accuracy on the human images, but it also detected 11% of the dog images as human faces.
To be able to recognise dogs in pictures, I used a pre-trained model ResNet-50. This model was trained using the ImageNet dataset, which has over 1 million images as training data and the same 133 dog breed categories as part of its output classes. The layer architecture used can be seen here. I tested this dog detector on the same set of images mentioned above and it achieved 100% accuracy on the dog images, and it didn’t detect any dogs in the human face dataset.
Data pre-processing
Keras CNNs requires a 4D array as input, with shape (nb_samples,rows,columns,channels), where nb_samples corresponds to the total number of images (or samples), and rows, columns, and channels correspond to the number of rows, columns, and channels for each image, respectively.
I created a function within the corresponding notebook to create this array (tensor). First, the function loads the image and resizes it to a square image. Next, the image is converted to an array, which is then resized to a 4D tensor. Since I planed to use pre-trained models, this function also included an additional normalization step that subtracts the mean pixel from every image. I rescale the images by dividing every pixel in every image by 255.
Model Summary
The following model architecture gave me the best results:
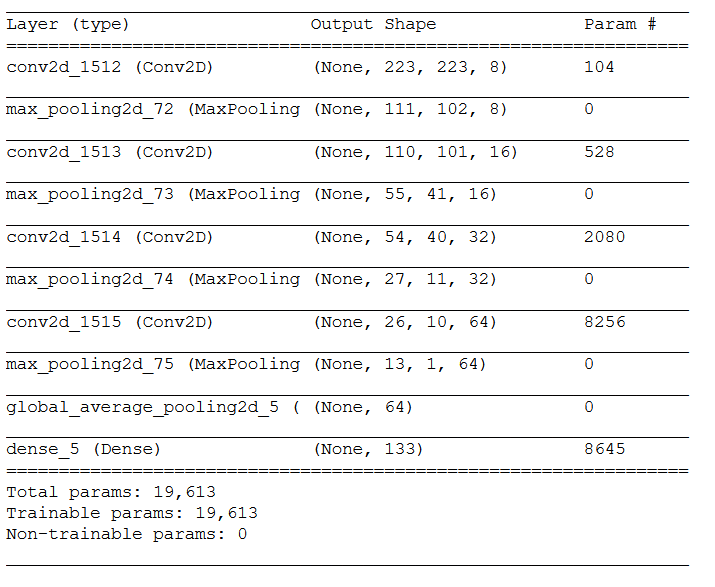
I defined four convolutional filters of increasing size (from 8 to 16 to 32 to 64). This is standard practice in building CNNs as I learned in the computer vision nanodegree I completed and other sources report as well. Furthermore I used stride length of 2 as it ran much faster and the use of stride length of 1 was not more accurate. I choosed GlobalAveragePooling as it is recommended in CNNs to reduce spatial dimensions. I used MaxPooling layer to reduce the dimensions of input images along CNN layers and should also counteract the danger of overfitting. We have used ‘rmsprop’ optimiser and ‘categorical_crossentropy’ as the loss function. Furthermore, it should be mentioned that I have used an epoch value of 5 to train this model with which a test accuracy of 5% could be achieved.
VGG-16 and Inception-V3
One of the reasons for such a poor accuracy value may be the limited amount of data. Since only 6,680 training images are available, the expectations for a completely new neural network from scratch with this amount of data cannot be high.
Transfer learning is an alternative solution to this problem. This involves using a pre-trained neural network that has been trained on a large amount of data. Such a network has already learned features that are useful for most computer vision problems, and using such features should allow us to achieve better accuracy than any method that would rely only on the available data.
For this purpose, we will use the VGG-16 architecture and the Inception-V3 architecture below.
VGG-16
First, I used the bottleneck features from VGG-16 model and added just the global average pooling and dense layers at the last. The optimiser (‘rmsprop’) and the loss function (‘categorical_crossentropy’) remain the same. The model was trained over 20 epochs and achieved a test accuracy of 68%.
Inception-V3
Afterwards I used the bottleneck features from InceptionV3 model to train a further classifier. As with the VGG-16 model as well, I added the global average pooling and dense layers at the last. I also added a Dropout layer to reduce overfitting.
Evaluation of the Inception-V3 model
The training and validation accuracies as well as the training and validation loss for first 50 epochs is shown below.
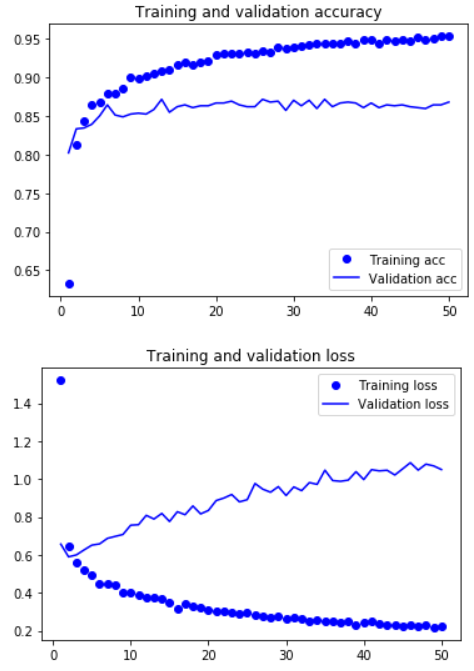
On the basis of this graph you can see that the model is still overfitting. This is probably because we are still using a very small data set with 133 categories and only 6,680 training images. This architecture out performs the VGG-16 architecture with a test accuracy of 79.55%.
Here are a few example output of the classifier:

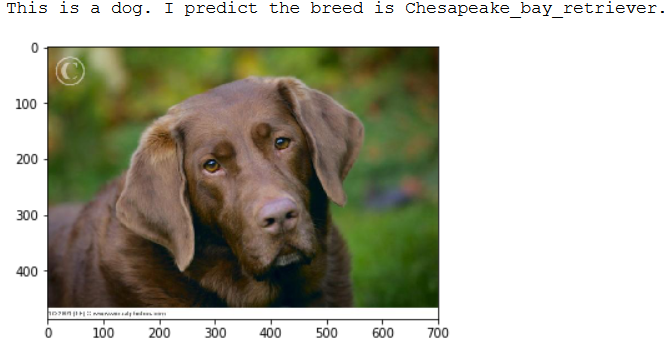


Conclusion
I started with a scratch CNN model with an accuracy of 5% and trained two models with 68% (VGG-16) and 79.55% (Inception-V3) accuracy using transfer learning.
My model performed as I expected, not perfect but good enough.
Now I can continue to fine tune the model by changing the hyper parameters and increasing the training data set to further improve the accuracy. The use of data augmentation can also help to increase the accuracy even further.
Acknowledgements
I thank Udacity for providing this challenge and learning experience.
GitHub Reopository
The code underlying this post is on my GitHub profile and can be accessed in full there.