1 Introduction
So far, we have already got to know several variants of ETL with which a large part of use cases can be covered.
But one important point has not been applied yet.
It often happens that the data has to be loaded or read out in an ‘unfavorable’ format. Especially with large data sets this can take hours until you have the possibility to edit the data to make the loading process more effective.
At this point it is worthwhile to save the loaded data only partially processed. So far we have always been lucky to be able to load, edit and save the data without any problems. But if, as en example, numerical values are formatted as strings, the loading process can take an infinite amount of time. Hence this post about the introduction of an ETL with intermediate storage.
Overview of the ETL steps:
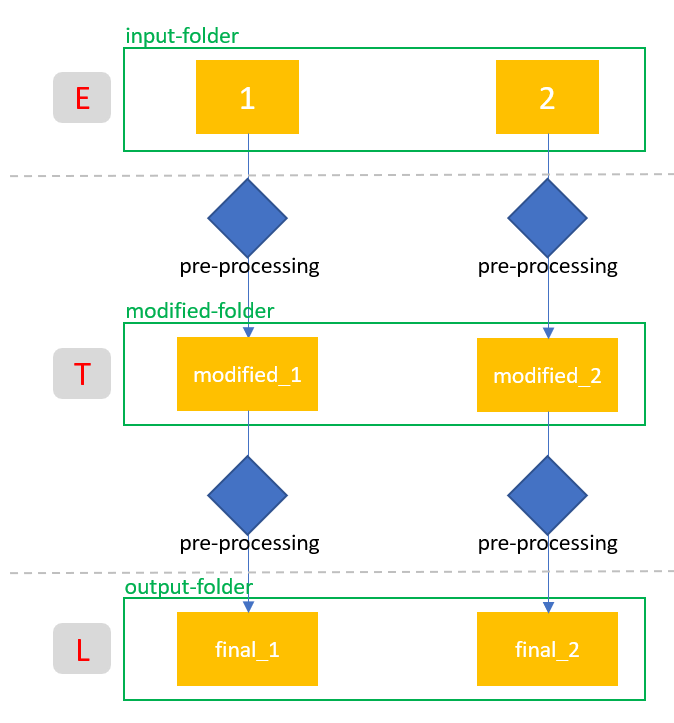
At the end I will test the created ETL. I will show this from another jupyter notebook and a fully automatic call from the command line.
For this post I use two specially created sample data sets. A copy of them is stored in my “GitHub Repo”.
2 Setup
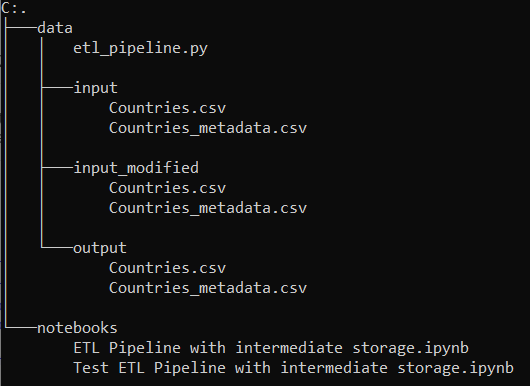
However, nothing changes in my used setup. The used data sets are stored under data/input, the ETL is also in the data folder and for the used notebooks an extra notebook folder was created.The input_modified and output folders are automatically created by the ETL if not already present.
3 ETL Pipeline with intermediate storage
import pandas as pd3.1 Extract
countries = pd.read_csv('../data/input/Countries.csv')
countries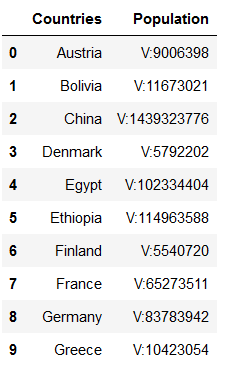
countries_metadata = pd.read_csv('../data/input/Countries_metadata.csv')
countries_metadata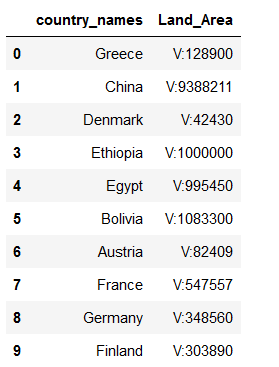
We notice, that the values are provided with the addition V for value. This leads to the fact that the variables Population and Land_Area are not numeric but objects. This can lead to considerable performance problems and long loading times, especially with large data sets. At this point it is recommended that the data set(s) be loaded once and saved temporarily. Then the ETL pipeline should access the modified files, process them accordingly and finally save it in the output folder for final analysis.
countries_metadata.dtypes
3.2 Transform_1
countries.Population = countries.Population.map(lambda x: x.split(':')[1])
countries['Population'] = countries['Population'].astype('int64')
countries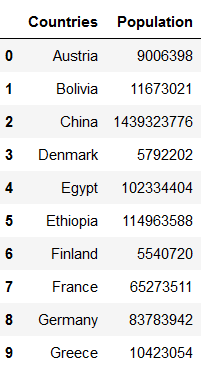
countries.dtypes
countries_metadata.Land_Area = countries_metadata.Land_Area.map(lambda x: x.split(':')[1])
countries_metadata['Land_Area'] = countries_metadata['Land_Area'].astype('int64')
countries_metadata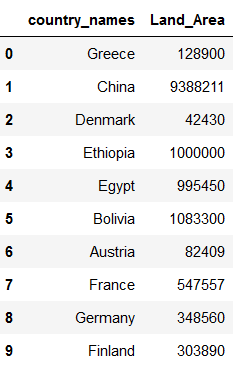
At this point we want to store the two datasets with the correct data types in the input_modified folder.
countries.to_csv('../data/input_modified/countries.csv')
countries_metadata.to_csv('../data/input_modified/output/countries_metadata.csv')3.3 Transform_2
Then we continue with the pre-processing steps.
countries['Population'] = countries['Population']/1000
countries = countries.rename(columns={'Population':'Population_per_k'})
countries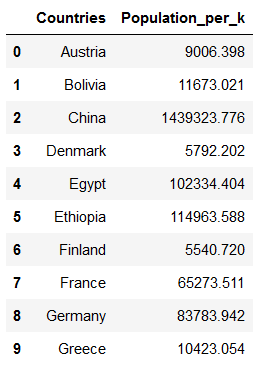
countries_metadata['Land_Area'] = countries_metadata['Land_Area']/1000
countries_metadata = countries_metadata.rename(columns={'Land_Area':'Land_Area_per_k'})
countries_metadata
3.4 Load
countries.to_csv('../data/output/countries.csv')
countries_metadata.to_csv('../data/output/countries_metadata.csv')4 Create etl_pipeline.py
import pandas as pd
import numpy as np
import os
class DataPreprocessor:
def __init__(self, path_folder = "path/to/data"):
self.path_folder = path_folder
# Path to input
self.path_input_folder = "{}/input/".format(path_folder)
self.path_input_countries = self.path_input_folder + 'Countries.csv'
self.path_input_countries_metadata = self.path_input_folder + 'Countries_metadata.csv'
# Path to modified input
self.path_input_modified_folder = "{}/input_modified/".format(path_folder)
self.path_input_modified_countries = self.path_input_modified_folder + 'Countries.csv'
self.path_input_modified_countries_metadata = self.path_input_modified_folder + 'Countries_metadata.csv'
# Path on which output tables are saved
self.path_output_folder = "{}/output/".format(path_folder)
self.path_output_countries = self.path_output_folder + 'Countries.csv'
self.path_output_countries_metadata = self.path_output_folder + 'Countries_metadata.csv'
# create dictionaries for read dtypes
self.read_dtypes_countries = {'Countries':'category'}
self.read_dtypes_countries_metadata = {'country_names':'category'}
# create folders for output if not existent yet
if not os.path.exists(self.path_input_modified_folder):
os.makedirs(self.path_input_modified_folder)
if not os.path.exists(self.path_output_folder):
os.makedirs(self.path_output_folder)
def read_data_from_raw_input(self, save_countries=True, save_countries_metadata=True):
print("Start:\tRead in countries Dataset")
self.countries = pd.read_csv(self.path_input_countries, dtype=self.read_dtypes_countries)
self.countries.Population = self.countries.Population.map(lambda x: x.split(':')[1])
self.countries['Population'] = self.countries['Population'].astype('int64')
print("Finish:\tRead in countries Dataset")
print("Start:\tRead in countries_metadata Dataset")
self.countries_metadata = pd.read_csv(self.path_input_countries_metadata, dtype=self.read_dtypes_countries_metadata)
self.countries_metadata.Land_Area = self.countries_metadata.Land_Area.map(lambda x: x.split(':')[1])
self.countries_metadata['Land_Area'] = self.countries_metadata['Land_Area'].astype('int64')
print("Finish:\tRead in countries_metadata Dataset")
if save_countries:
print("Start:\tSave countries Dataset to disc")
self.countries.to_csv(self.path_input_modified_countries, index=False)
print("Finish:\tSave countries Dataset to disc")
if save_countries_metadata:
print("Start:\tSave countries_metadata Dataset to disc")
self.countries_metadata.to_csv(self.path_input_modified_countries_metadata, index=False)
print("Finish:\tSave countries_metadata Dataset to disc")
def read_data_from_modified_input(self):
self.countries = pd.read_csv(self.path_input_modified_countries, dtype=self.read_dtypes_countries)
self.countries_metadata = pd.read_csv(self.path_input_modified_countries_metadata, dtype=self.read_dtypes_countries_metadata)
def preprocess_data(self, save_preprocess_countries=True, save_preprocess_countries_metadata=True):
print("Start:\tPreprocessing countries Dataset")
self.preprocess_countries()
print("Finish:\tPreprocessing countries Dataset")
print("Start:\tPreprocessing countries_metadata Dataset")
self.preprocess_countries_metadata()
print("Finish:\tPreprocessing countries_metadata Dataset")
if save_preprocess_countries:
print("Start:\tSave countries Dataset to disc")
self.countries.to_csv(self.path_output_countries, index=False)
print("Finish:\tSave countries Dataset to disc")
if save_preprocess_countries_metadata:
print("Start:\tSave countries_metadata Dataset to disc")
self.countries_metadata.to_csv(self.path_output_countries_metadata, index=False)
print("Finish:\tSave countries_metadata Dataset to disc")
return self.countries, self.countries_metadata
def preprocess_countries(self):
self.countries['Population'] = self.countries['Population']/1000
self.countries = self.countries.rename(columns={'Population':'Population_per_k'})
def preprocess_countries_metadata(self):
self.countries_metadata['Land_Area'] = self.countries_metadata['Land_Area']/1000
self.countries_metadata = self.countries_metadata.rename(columns={'Land_Area':'Land_Area_per_k'})
def read_preprocessed_tables(self):
print("Start:\tRead in modified countries Dataset")
self.countries = pd.read_csv(self.path_output_countries, dtype=self.read_dtypes_countries)
print("Finish:\tRead in modified countries Dataset")
print("Start:\tRead in modified countries_metadata Dataset")
self.countries_metadata = pd.read_csv(self.path_output_countries_metadata, dtype=self.read_dtypes_countries_metadata)
print("Finish:\tRead in modified countries_metadata Dataset")
return self.countries, self.countries_metadata
def main():
datapreprocesssor = DataPreprocessor()
datapreprocesssor.read_data_from_raw_input()
datapreprocesssor.read_data_from_modified_input()
datapreprocesssor.preprocess_data()
print('ETL has been successfully completed !!')
#if __name__ == '__main__':
# main()We have commented out the main from the ETL pipeline here with ‘#’. Of course, this syntax must not be commented out in the .py file.
Unfortunately the view is not optimal. Therefore I recommend to copy the syntax into a .py file. I prefer “Visual Studio Code” from Microsoft. But I also put the file in my “GitHub Repo” from where you can get it.
5 Test etl_pipeline.py
Now we want to test our created ETL with intermediate storage.
5.1 from jupyter notebook
First I want to test the ETL from a notebook. For this we create and start a new notebook in the notebooks-folder with the name ‘Test ETL Pipeline with intermediate storage.ipynb’.
With this ETL we have the special feature that the (assumed) initial loading takes an extremely long time. Once this step has been taken there is no way around it. But with intermediate storage we can reduce the runtime of the ETL (step 5.1.2 and 5.1.3) considerably.
5.1.1 the very first time
import sys
# Specifies the file path where the first .py file is located.
sys.path.insert(1, '../data')
import etl_pipelinedatapreprocessor = etl_pipeline.DataPreprocessor()
datapreprocessor.read_data_from_raw_input(save_countries=True, save_countries_metadata=True)
datapreprocessor.read_data_from_modified_input()
countries, countries_metadata = datapreprocessor.preprocess_data(save_preprocess_countries=True, save_preprocess_countries_metadata=True)
countries, countries_metadata = datapreprocessor.read_preprocessed_tables()
countries
countries_metadata
5.1.2 when u changed sth. within preprocess_data
import sys
# Specifies the file path where the first .py file is located.
sys.path.insert(1, '../data')
import etl_pipelinedatapreprocessor = etl_pipeline.DataPreprocessor()
datapreprocessor.read_data_from_modified_input()countries, countries_metadata = datapreprocessor.preprocess_data(save_preprocess_countries=True, save_preprocess_countries_metadata=True)
countries, countries_metadata = datapreprocessor.read_preprocessed_tables()
countries
countries_metadata
5.1.3 when u continue with analytics
import sys
# Specifies the file path where the first .py file is located.
sys.path.insert(1, '../data')
import etl_pipelinedatapreprocessor = etl_pipeline.DataPreprocessor()
countries, countries_metadata = datapreprocessor.read_preprocessed_tables()
countries
countries_metadata
5.2 from command line
Because we have defined a main in the .py file we are able to call and execute the ETL from the command line. It does not matter which command line this is exactly. You can use Anaconda Power Shell, Git Bash, the Windwos Comman Line or anything else.
Type only the following commands in your command prompt:
cd "path/to/your/data/folder"
python etl_pipeline.pyAs the main is currently written in the etl_pipeline.py, all steps (including the first loading step with a long runtime) are executed. If you don’t want or need this (as described in one of the steps above from within the jupyter notebook) you would have to adapt the main accordingly and comment out some commands.
6 Conclusion
In this example, we assumed that due to the wrong formatting of the original data types, the loading time of the data records is extremely high. In such a case the data would be cached to make it more accessible for everyday use (further development of the ETL and pre-processing steps as well as analytics).