1 Introduction
I already wrote about feature selection for regression analysis in this “post”. Feature selection is also relevant for classification problems. And that’s what this post is about.
For this publication the dataset MNIST from the statistic platform “Kaggle” was used. A copy of the record is available at https://drive.google.com/open?id=1Bfquk0uKnh6B3Yjh2N87qh0QcmLokrVk.
2 Loading the libraries and the data
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
# For chapter 4.1
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
# For chapter 4.2 & 4.3
from mlxtend.feature_selection import SequentialFeatureSelector
from sklearn.ensemble import RandomForestClassifier
# For chapter 4.4
from sklearn.feature_selection import RFE
# For chapter 4.5
from mlxtend.feature_selection import ExhaustiveFeatureSelectormnist = pd.read_csv('path/to/file/mnist_train.csv')We already know the data set used from the “OvO and OvR Classifier - Post”. For a detailed description see also “here”.
As we can see, the MNIST dataset has 785 columns. Reason enough to use feature selection.
mnist.shape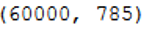
But first of all let’s split our dataframe:
x = mnist.drop('label', axis=1)
y = mnist['label']
trainX, testX, trainY, testY = train_test_split(x, y, test_size = 0.2)3 Filter methods
The filter methods that we used for “regression tasks” are also valid for classification problems.
Check out these publications to find out exactly how these methods work. In this post we have omitted the use of filter methods for the sake of simplicity and will go straight to the wrapper methdods.
4 Wrapper methods
As already mentioned above, I described the use of wrapper methods for regression problems in this “post: Wrapper methods”. If you want to know exactly how the different wrapper methods work and how they differ from filter methods, please read “here”.
The syntax changes only slightly with classification problems.
4.1 SelectKBest
selector = SelectKBest(score_func=chi2, k=20)
selector.fit(trainX, trainY)
vector_names = list(trainX.columns[selector.get_support(indices=True)])
print(vector_names)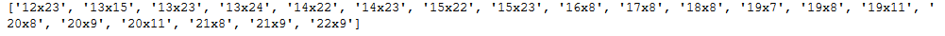
trainX_best = trainX[vector_names]
testX_best = testX[vector_names]
print(trainX_best.shape)
print(testX_best.shape)
4.2 Step Forward Feature Selection
We continue to work on the remaining wrapper methods with the selection by SelectKBest. Furthermore, the classification algorithm Random Forest was used for the other wrapper methods.
clf = RandomForestClassifier(n_jobs=-1)
# Build step forward feature selection
feature_selector = SequentialFeatureSelector(clf,
k_features=5,
forward=True,
floating=False,
verbose=2,
scoring='accuracy',
cv=5)
features = feature_selector.fit(trainX_best, trainY)filtered_features= trainX_best.columns[list(features.k_feature_idx_)]
filtered_features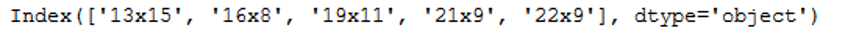
New_train_x = trainX_best[filtered_features]
New_test_x = trainX_best[filtered_features]4.3 Backward Elimination
clf = RandomForestClassifier(n_jobs=-1)
feature_selector = SequentialFeatureSelector(clf,
k_features=5,
forward=False,
floating=False,
verbose=2,
scoring='accuracy',
cv=5)
features = feature_selector.fit(trainX_best, trainY)filtered_features= trainX_best.columns[list(features.k_feature_idx_)]
filtered_features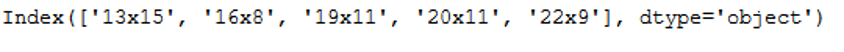
New_train_x = trainX_best[filtered_features]
New_test_x = trainX_best[filtered_features]4.4 Recursive Feature Elimination (RFE)
clf = RandomForestClassifier(n_jobs=-1)
rfe = RFE(clf, n_features_to_select=5)
rfe.fit(trainX_best,trainY)rfe.support_
rfe.ranking_
Columns = trainX_best.columns
RFE_support = rfe.support_
RFE_ranking = rfe.ranking_
dataset = pd.DataFrame({'Columns': Columns, 'RFE_support': RFE_support, 'RFE_ranking': RFE_ranking}, columns=['Columns', 'RFE_support', 'RFE_ranking'])
dataset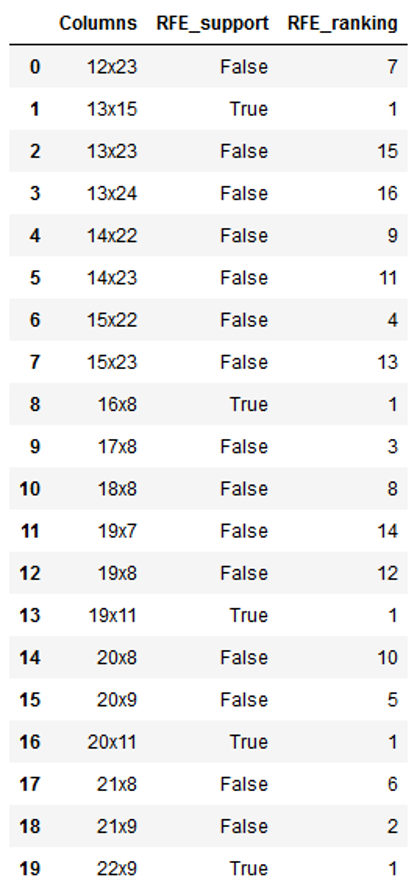
df = dataset[(dataset["RFE_support"] == True) & (dataset["RFE_ranking"] == 1)]
filtered_features = df['Columns']
filtered_features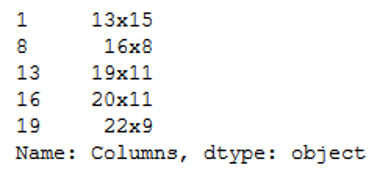
New_train_x = trainX_best[filtered_features]
New_test_x = trainX_best[filtered_features]4.5 Exhaustive Feature Selection
The method of the Exhaustive Feature Selection is new and is therefore explained in a little more detail.
In exhaustive feature selection, the performance of a machine learning algorithm is evaluated against all possible combinations of the features in the dataframe. The exhaustive search algorithm is the most greedy algorithm of all the wrapper methods shown above since it tries all the combination of features and selects the best. The algorithm has min_featuresand max_features attributes which can be used to specify the minimum and the maximum number of features in the combination.
As already mentioned Exhaustive Feature Selection is very computationaly expensive. Therefore, we use SelectKBest again, but this time we only let us calculate the 10 best features.
selector = SelectKBest(score_func=chi2, k=10)
selector.fit(trainX, trainY)
vector_names = list(trainX.columns[selector.get_support(indices=True)])
trainX_best = trainX[vector_names]
testX_best = testX[vector_names]Furthermore we set the parameter cv to 2. Normaly I set cv=5.
clf = RandomForestClassifier(n_jobs=-1)
feature_selector = ExhaustiveFeatureSelector(clf,
min_features=2,
max_features=5,
scoring='accuracy',
print_progress=True,
cv=2)
features = feature_selector.fit(trainX_best, trainY)filtered_features= trainX_best.columns[list(features.best_idx_)]
filtered_features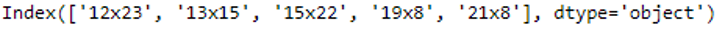
New_train_x = trainX_best[filtered_features]
New_test_x = trainX_best[filtered_features]5 Conclusion
This post showed how to use wrapper methods for classification problems.