1 Introduction
In addition to “removing highly correlated features” as one of the data pre processing steps we also have to take care of constant and duplicate features. Constant features have a variance close to zero and duplicate features are too similar to other variables in the record. Therefore, when pre-processing data for regression analysis, its existence should be checked and, if so, excluded.
For this post the dataset Santandar Customer Satisfaction (only the train-part) from the statistic platform “Kaggle” was used. You can download it from my GitHub Repository.
2 Loading the libraries and the data
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import VarianceThresholdsantandar_data = pd.read_csv("path/to/file/santandar.csv")santandar_data.shape
3 Removing Constant features
Constant features provide no information that can help for further analysis. Therefore we have to remove them from the dataframe. We can find the constant features using the ‘VarianceThreshold’ function of Python’s Scikit Learn Library.
As we can see in the output of the code shown above, we have 371 columns and over 76 thousand observations.
x = santandar_data.drop(['TARGET', 'ID'], axis = 1)
y = santandar_data['TARGET']
trainX, testX, trainY, testY = train_test_split(x, y, test_size = 0.2, random_state=45)As already mentioned in the post “Dealing with highly correlated features” it is important that, in order to avoid overfitting, feature selection should only be applied to the training set.
trainX.shape
Next we will use VarianceThreshold function to remove constant features.
constant_filter = VarianceThreshold(threshold=0)In the next step, we need to simply apply this filter to our training set as shown in the following:
constant_filter.fit(trainX)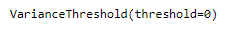
Now we want to get all the features that are not constant (features we want to keep):
len(trainX.columns[constant_filter.get_support()])
Similarly, you can find the number of constant features with the help of the following code:
constant_columns = [column for column in trainX.columns
if column not in trainX.columns[constant_filter.get_support()]]
print(len(constant_columns))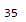
As we can see, there are 35 variables with zero variance. We can also print their column name:

In the last step these 35 variables have to be removed from the training and test part. We can do this as follows:
constant_columns_to_remove = [i.strip() for i in constant_columns]trainX = trainX.drop(constant_columns_to_remove, axis=1)
trainX.shape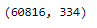
testX = testX.drop(constant_columns_to_remove, axis=1)
testX.shape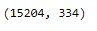
4 Removing Quasi-Constant features
Quasi-constant features are the features that are almost constant. Where we have chosen a variance threshold of 0 at constant features, we can now adjust this arbitrarily. The procedure is almost the same as the previous one. It is recommended to examine the quasi-Constant features in the already reduced training and test data set.
Instead of passing again 0 as the value for the threshold parameter, we now will pass 0.01, which means that if the variance of the values in a column is less than 0.01, remove that column.
qconstant_filter = VarianceThreshold(threshold=0.01)qconstant_filter.fit(trainX)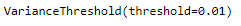
len(trainX.columns[qconstant_filter.get_support()])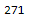
qconstant_columns = [column for column in trainX.columns
if column not in trainX.columns[qconstant_filter.get_support()]]
print(len(qconstant_columns))
63 columns were identified as quasi-Constant features. We can request these column names of this variables again with the following command:
for column in qconstant_columns:
print(column)
Afterwards they will be removed as well.
qconstant_columns_to_remove = [i.strip() for i in qconstant_columns]trainX = trainX.drop(qconstant_columns_to_remove, axis=1)
trainX.shape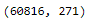
testX = testX.drop(qconstant_columns_to_remove, axis=1)
testX.shape
5 Removing Duplicate Features
As a final step we dedicate ourselves to the duplicate features. Hereby the procedure is a little different because we have no suitable function from the Scikit-learn library available.
trainX_T = trainX.T
trainX_T.shape
In the following way we will receive the number of duplicate features:
print(trainX_T.duplicated().sum())
In the following way we will receive the number of features we will keep for further analysis:
unique_features = trainX_T.drop_duplicates(keep='first').T
unique_features.shape
Now we define a list of duplicate features we have to remove:
duplicated_features = [dup_col for dup_col in testX.columns if dup_col not in unique_features.columns]
duplicated_features
… and remove them:
trainX = trainX.drop(duplicated_features, axis=1)
trainX.shape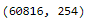
testX = testX.drop(duplicated_features, axis=1)
testX.shape
6 Conclusion
As we can see in the following overview, a dataset can be greatly reduced by identifying and excluding duplicate features or some with zero variance.

There are several advantages of performing feature selection before training machine learning models:
- Models with less number of features have higher explainability
- Fewer features lead to enhanced generalization which in turn reduces overfitting
- Models with fewer features are less prone to errors
- Training time of models with fewer features is significantly lower