1 Introduction

Image Source: “Statsmodels.org”
In my post “Introduction to regression analysis and predictions” I used the statsmodel library to identify significant features influencing the property price. In this publication I would like to show the difference of the statsmodel.formula.api (smf) and the statsmodel.api (sm).
For this post the dataset House Sales in King County, USA from the statistic platform “Kaggle” was used. You can download it from my GitHub Repository.
2 Loading the libraries and the data
import pandas as pd
import numpy as np
#for chapter 3
import statsmodels.formula.api as smf
#for chapter 4
import statsmodels.api as smhouse_prices = pd.read_csv("path/to/file/house_prices.csv")As a simplified example, only the features ‘sqft_living’, ‘bedrooms’ & ‘yr_built’ and the target variable ‘price’ from the data set are used.
mult_reg = house_prices[['price', 'sqft_living', 'bedrooms', 'yr_built']]
mult_reg.head()
3 The statsmodel.formula.api
As we know from the post “Introduction to regression analysis and predictions (chapter 3.2, model3)”, the predictors in the statsmodel formula api must be enumerated individually.
SMF_model = smf.ols(formula='price~sqft_living+bedrooms+yr_built', data=mult_reg).fit()Let’s print the summary:
print(SMF_model.summary())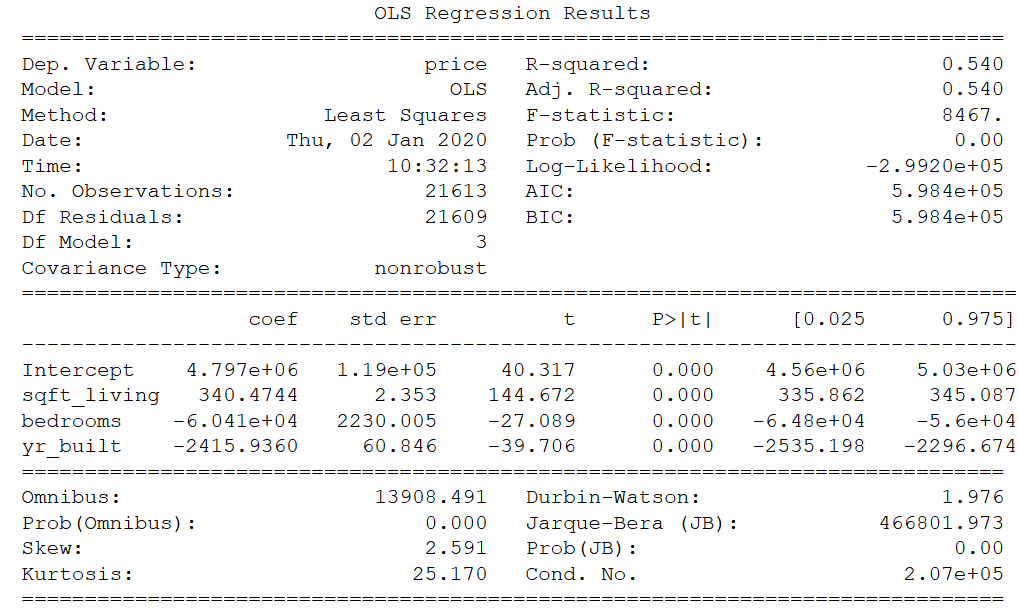
OK, as in “Introduction to regression analysis and predictions”, we get an R² of .54.
print('R²: ', SMF_model.rsquared)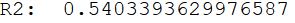
But what is the difference between the statsmodel.formula.api and the statsmodel.api ??
4 The statsmodel.api
The main difference between smf and sm is that the predictors no longer have to be enumerated individually. They can be assigned to an object as in the scikit-learn library. This can be extremely helpful, especially with large data sets that have many variables.
x = mult_reg.drop('price', axis=1)
y = mult_reg['price']
SM_model = sm.OLS(y, x).fit()Let’s print the summary again:
print(SM_model.summary())
Mh wait a minute … why do we get an R² of .84 this time??
print('R²: ', SM_model.rsquared)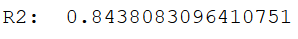
The reason is that in statsmodel.formula.api a constant is automatically added to the data and an intercept in fitted. In statsmodels.api, you have to add a constant yourself! You can do that using the .add_constant() function.
x_new = sm.add_constant(x)
x_new.head()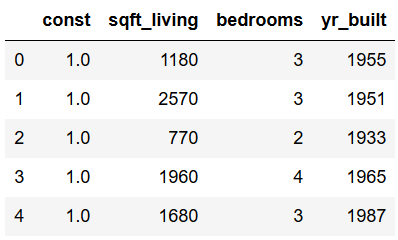
Let’s create our model again…
SM_model_2 = sm.OLS(y, x_new).fit()..and print the results:
print(SM_model_2.summary())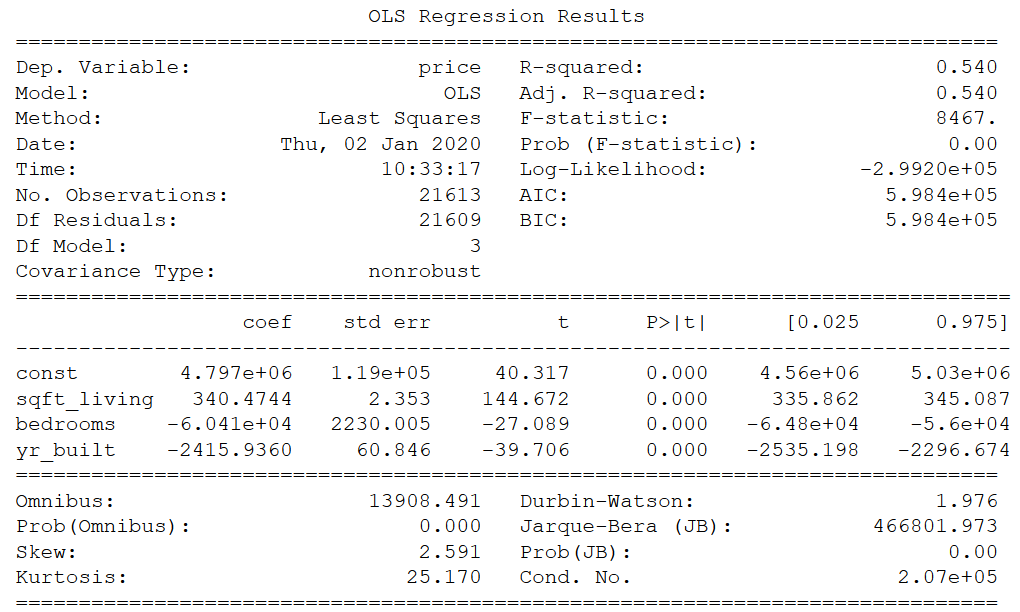
Perfect, we get an R² of .54 again.
print('R²: ', SM_model_2.rsquared)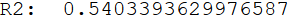
5 Conclusion
The main difference between the statsmodel.formula.api (smf) and the statsmodel.api (sm) was discussed in this post.