1 Introduction

As mentioned in my previous “post”, before you can start modeling, a lot of preparatory work is often necessary when preparing the data. In this post the most common encoding algorithms from the scikit-learn library will be presented and how they are to be used.
2 Loading the libraries and the data
import numpy as np
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
from sklearn.preprocessing import OrdinalEncoder
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import LabelEncoder
import pickle as pkdf = pd.DataFrame({'Job': ['Doctor', 'Farmer', 'Electrician', 'Teacher', 'Pilot'],
'Emotional_State': ['good', 'bad', 'neutral', 'very_good', 'excellent'],
'Age': [32,22,62,44, 54],
'Salary': [4700, 2400,4500,2500, 3500],
'Purchased': ['Yes', 'No', 'No', 'Yes', 'No']})
df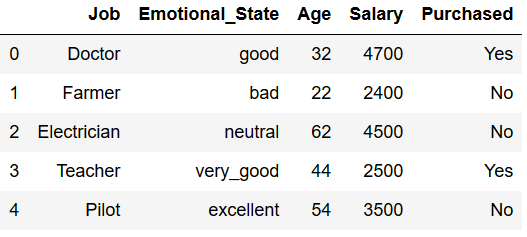
3 Encoder for predictor variables
3.1 One Hot Encoder
I already wrote about the functioning and creation of dummy variables in my post “The use of dummy variables”. In scikit-learn this function is known as One Hot Encoding.
3.1.1 via scikit-learn
In a nutshell One Hot Encoder encode categorical features as a one-hot numeric array:
encoder = OneHotEncoder()
OHE = encoder.fit_transform(df.Job.values.reshape(-1,1)).toarray()
df_OH = pd.DataFrame(OHE, columns = ["Job_" + str(encoder.categories_[0][i])
for i in range(len(encoder.categories_[0]))])
df_OH_final = pd.concat([df, df_OH], axis=1)
df_OH_final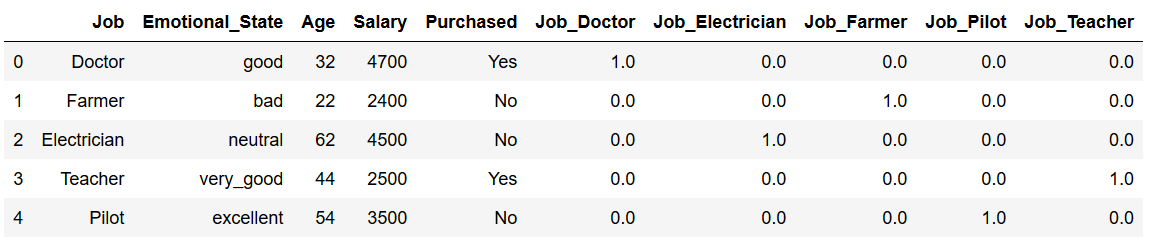
3.1.2 via pandas
df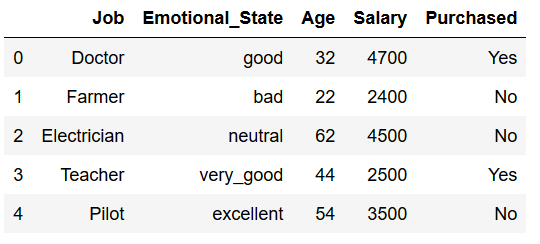
You can also create dummy variables with the .get_dummies function from pandas.
This method is faster than the one just shown via scikit-learn but it also has a big disadvantage! Here the mapping is not saved. But it can still be used to quickly test if creating / using dummy variables improves the model result. If the generated features contribute to an improved result, the One Hot Encoder from scikit-learn should be used in any case.
df_dummies = pd.get_dummies(df, prefix=['Job'], columns=['Job'])
df_dummies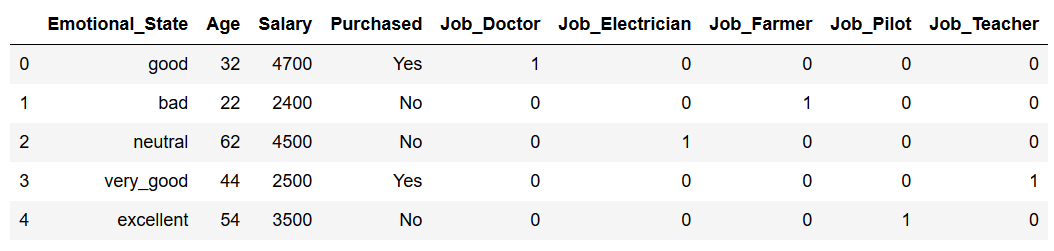
How to use this function in data analysis is explained in detail in this “post”.
3.2 Ordinal Encoder
In some cases, categorical variables follow a certain order (in our example here, this is the column ‘Emotional_State’).
df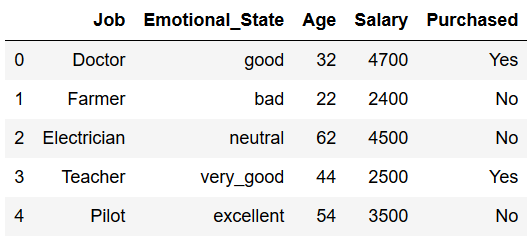
Hereby One hot encoding would result in the loss of valuable information (ranking). Here you can see how the Ordinal Encoder from scikit-learn works:
encoder = OrdinalEncoder()
ord_Emotional_State = encoder.fit_transform(df.Emotional_State.values.reshape(-1,1))
ord_Emotional_State
Now we insert the generated array into the existing dataframe:
df['ord_Emotional_State'] = ord_Emotional_State
df['ord_Emotional_State'] = df['ord_Emotional_State'].astype('int64')
df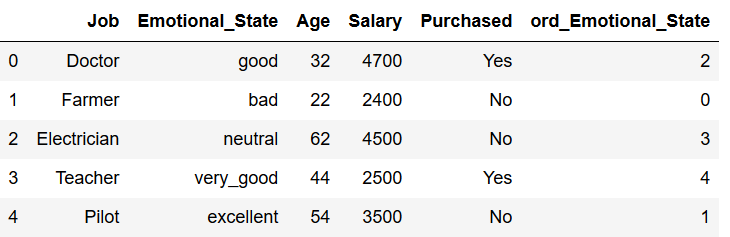
But in my opinion Ordinal Encoder from scikit-learn has a big disadvantage. The order is assigned arbitrarily:
df[['Emotional_State', 'ord_Emotional_State']].sort_values(by='ord_Emotional_State', ascending=False)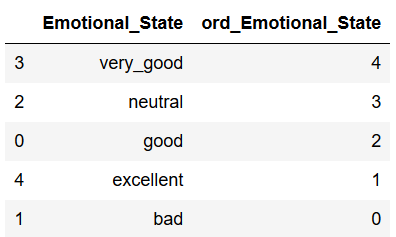
The assigned order makes little sense in reality. I would therefore suggest the following method. A sensible order is first defined and then mapped to the desired variable:
Emotional_State_dict = {'bad' : 0,
'neutral' : 1,
'good' : 2,
'very_good' : 3,
'excellent' : 4}
df['Emotional_State_Ordinal'] = df.Emotional_State.map(Emotional_State_dict)
df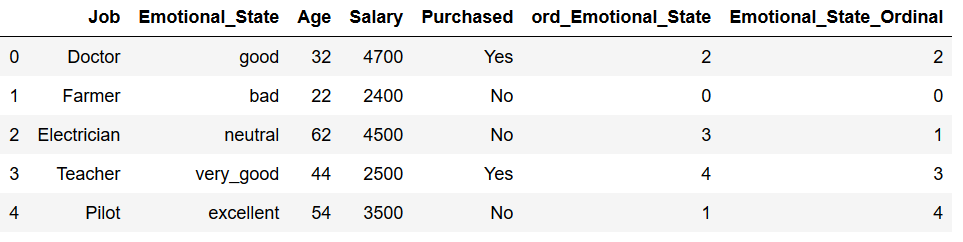
Now we have a sensible order:
df[['Emotional_State', 'Emotional_State_Ordinal']].sort_values(by='Emotional_State_Ordinal', ascending=False)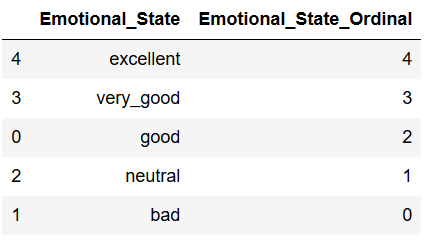
3.3 MultiLabelBinarizer
MultiLabelBinarizer basically works something like One Hot Encoding. The difference is that for a given column, a row can contain not only one value but several. Have a look at this example:
df = pd.DataFrame({"genre": [["action", "drama","fantasy"], ["fantasy","action", "animation"], ["drama", "action"], ["sci-fi", "action"]],
"title": ["Twilight", "Alice in Wonderland", "Tenet", "Star Wars"]})
df
Here we have assigned multiple genres for each film listed. Makes sense. To create a matrix with one column for each genre listed we need MultiLabelBinarizer.
mlb = MultiLabelBinarizer()
res = pd.DataFrame(mlb.fit_transform(df['genre']),
columns=mlb.classes_,
index=df['genre'].index)
res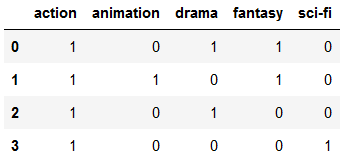
Now all we have to do is delete the old column from the original data set and merge the two data sets (df and res).
df = df.drop('genre', axis=1)
df = pd.concat([df, res], axis=1, sort=False)
df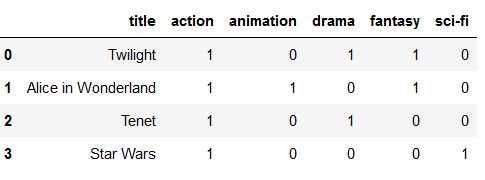
That’s it.
4 Encoder for target variables
Before that, we looked at which encoding methods make sense for predictor variables. Now let’s look at which ones make sense for target variables.
4.1 Label Binarizer
Let’s have a look at the original dataframe.
df = df.drop(['ord_Emotional_State', 'Emotional_State_Ordinal'], axis=1)
df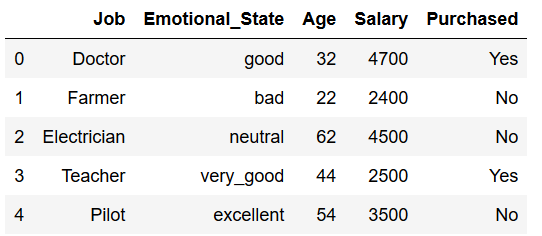
The Label Binarizer function from scikit-learn is able to convert binary variables (variables with only two classes) into numerical values (0 & 1).
encoder = LabelBinarizer()
encoded_Purchased = encoder.fit_transform(df.Purchased.values.reshape(-1,1))
encoded_Purchased
Now we are integrating this array back into our data set:
df['Purchased_Encoded'] = encoded_Purchased
df['Purchased_Encoded'] = df['Purchased_Encoded'].astype('int64')
df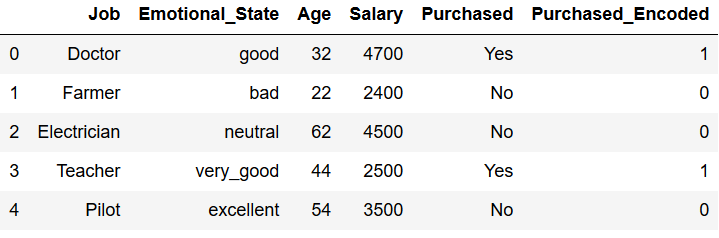
4.2 Label Encoding
Unfortunately the label binarizer is no longer sufficient to prepare the data for multiclass classification algorithms. Hereby we need Label Encoding. In the following example, the column ‘Job’ should be our target variable.
df = df[['Emotional_State', 'Salary', 'Purchased', 'Job']]
df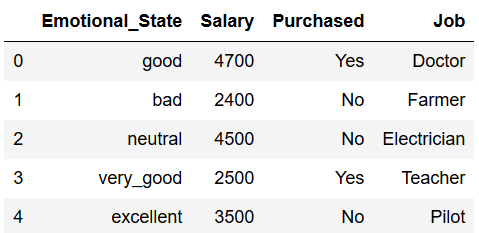
The Label Encoder now generates a numerical value for each individual class within this categorical variable.
encoder = LabelEncoder()
df['Job_Encoded'] = encoder.fit_transform(df.Job)
df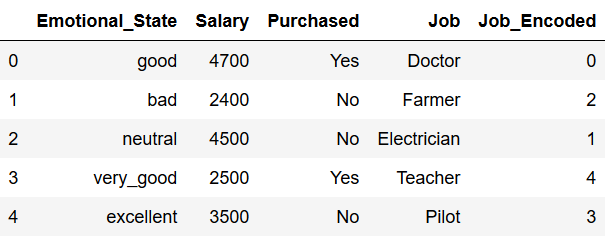
The syntax below shows which class has been assigned which value.
target = df['Job']
integerEncoded = encoder.fit_transform(target)
integerMapping=dict(zip(target,integerEncoded))
integerMapping
You can also use the .inverse_transform function to find out which classes have been assigned the values (here) 0 and 1.
encoder.inverse_transform([0, 1])
Finally, it is shown how to apply the .inverse_transform function to an entire column and add it back to the original dataframe.
target_encoded = df['Job_Encoded']
invers_transformed = encoder.inverse_transform(target_encoded)
df['Job_Invers_Transformed'] = invers_transformed
df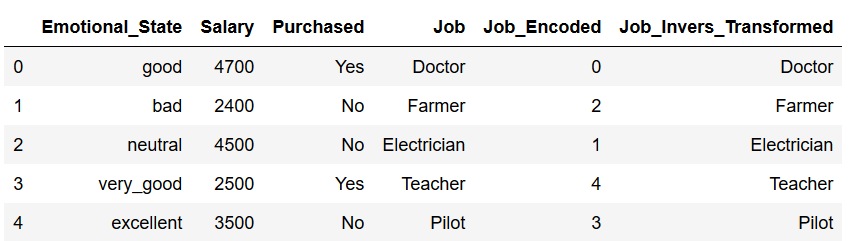
I would not recommend the use of this encoder for predictor variables, because the assigned order (0 < 1 < 2 < 3 …) could have an incorrect influence on the model. Use One Hot Encoding instead.
5 Inverse Transformation
Now that we have learned some methods of encoding I would like to introduce the inverse_transform function. The encoding of data is usually a necessary step for the training of machine learning algorithms. For a good interpretation of the results it is usually advantageous to transform the coded data back again. But this is easy to do.
We take this dataframe as an example:
df = pd.DataFrame({'Job': ['Doctor', 'Farmer', 'Electrician', 'Teacher', 'Pilot'],
'Emotional_State': ['good', 'bad', 'neutral', 'very_good', 'excellent'],
'Age': [32,22,62,44, 54],
'Salary': [4700, 2400,4500,2500, 3500],
'Purchased': ['Yes', 'No', 'No', 'Yes', 'No']})
df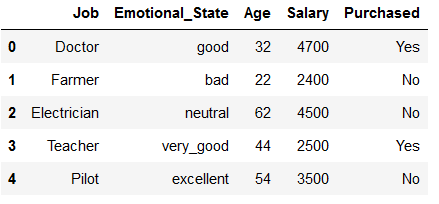
and use one-hot encoding again:
encoder = OneHotEncoder()
OHE_fit = encoder.fit(df.Job.values.reshape(-1,1))
OHE_transform = OHE_fit.transform(df.Job.values.reshape(-1,1)).toarray()
OHE_transform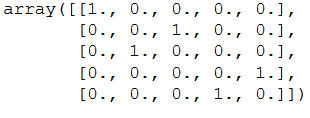
Can save the result as before in a dataframe. Both methods work.
df_OHE = pd.DataFrame(OHE_transform, columns = ["Job_" + str(encoder.categories_[0][i])
for i in range(len(encoder.categories_[0]))])
df_OHE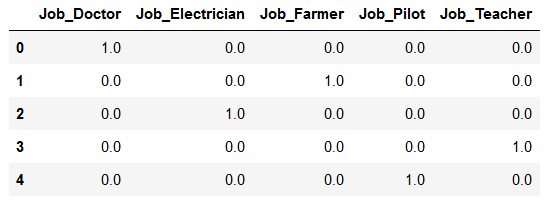
Now we are ready to use the inverse_transform function.
re_transformed_array = encoder.inverse_transform(OHE_transform)
re_transformed_array
re_transformed_df = encoder.inverse_transform(df_OHE)
re_transformed_df
As we can see the inverse_transform function works with the created array as well as with the created dataframe. Now I append the re_transformed_array to the dataframe (df_OHE).
df_OHE['inverse_transform'] = re_transformed_array
df_OHE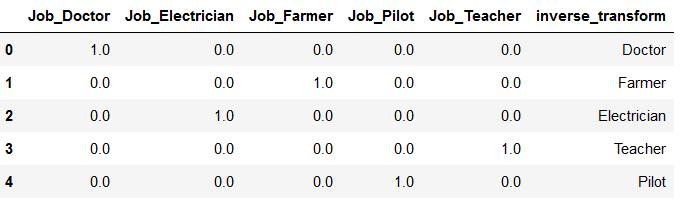
6 Export Encoder to use in another program
When we develop machine learning algorithms it is important to store the (in our current case) encoders separately so that they can be used again later.
pk.dump(encoder, open('encoder.pkl', 'wb'))
Now we reload the just saved encoder (encoder.pkl).
encoder_reload = pk.load(open("encoder.pkl",'rb'))Now let’s test the reloaded encoder with the following dataframe.
df_new = pd.DataFrame({'Job_Doctor': [1,0,0,0,0],
'Job_Electrician': [0,1,0,0,0],
'Job_Farmer': [0,0,0,0,1],
'Job_Pilot': [0,0,0,1,0],
'Job_Teacher': [0,0,1,0,0]})
df_new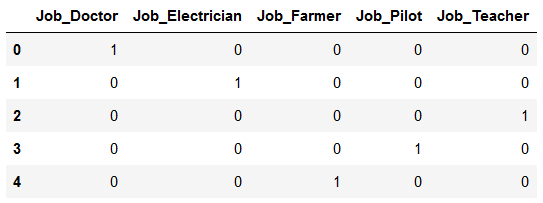
re_transformed_df_new = encoder_reload.inverse_transform(df_new)
re_transformed_df_new
It works!
Of course you will need less the inverse_transform function of a stored encoder, but the advantage of an already fitted encoder is that you will notice immediately if something has changed compared to the original files (which you also used during training).
What do I mean specifically?
Suppose we have developed an algorithm using OneHotEncoding to prepare the data. Now we get new data on the basis of which we should make new predictions. Logically we have to convert the categorical data into numerical data (via OHE). Ideally in exactly the same way as with the original data on which the training of the used algorithm is based.
Therefore we store the encoder separately and load it for new data to practice OHE. This way we can be sure that
- we get the same encoding and
- we also have the same learned categories.
If new categories are added and the encoder is applied to the wrong column, we will see this immediately as the following examples will show.
df_dummy1 = pd.DataFrame({'Job': ['Doctor', 'Farmer', 'Electrician', 'Teacher', 'Pilot'],
'Emotional_State': ['good', 'bad', 'neutral', 'very_good', 'excellent'],
'Age': [32,22,62,44, 54],
'Salary': [4700, 2400,4500,2500, 3500],
'Purchased': ['Yes', 'No', 'No', 'Yes', 'No']})
df_dummy1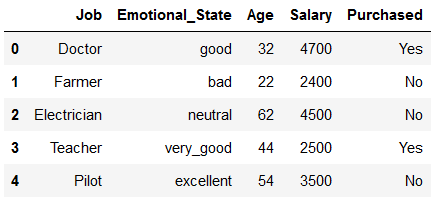
test_df_dummy1 = encoder_reload.transform(df_dummy1.Emotional_State.values.reshape(-1,1)).toarray()
test_df_dummy1
Here we have specified a wrong column on which the encoder was not trained.
df_dummy1_part2 = pd.DataFrame({'Job': ['craftsman', 'merchant', 'sales']})
df_dummy1_part2
test_df_dummy1_part2 = encoder_reload.transform(df_dummy1_part2.Job.values.reshape(-1,1)).toarray()
test_df_dummy1_part2
Here we have tried to apply the encoder to new categories. Logically this does not work either. In such a case, the training of the algorithm would have to be reset.
df_dummy2 = pd.DataFrame({'Job_A': [1,0,0,0,0],
'Job_B': [0,1,0,0,0],
'Job_C': [0,0,0,0,1],
'Job_D': [0,0,0,1,0],
'Job_E': [0,0,1,0,0]})
df_dummy2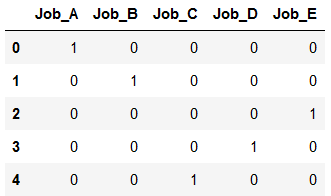
test_df_dummy2 = encoder_reload.inverse_transform(df_dummy2)
test_df_dummy2
In this example we changed the column names but used the same number. This works technically but the result makes no sense.
df_dummy3 = pd.DataFrame({'Job_A': [1,0,0,0,0],
'Job_B': [0,1,0,0,0],
'Job_C': [0,0,0,0,1],
'Job_D': [0,0,0,1,0]})
df_dummy3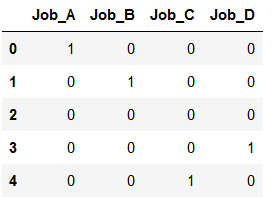
test_df_dummy3 = encoder_reload.inverse_transform(df_dummy3)
test_df_dummy3
Here we have now left out a column. The reloaded encoder does not allow this either.
7 Conclusion
Here is a brief overview of which encoding methods are available and when to use them:
One Hot Encoder: Generates additional features by transforming categorical variables and converts them into numerical values.
Ordinal Encoder: Transforms categorical variables into numerical ones and puts them in a meaningful order.
Label Binarizer: Transforms a categorical target variable into a binary numeric value.
Label Encoding: Transforms the classes of a multiclass categorical target variable into a numeric value.