1 Introduction
In a nutshell: a dummy variable is a numeric variable that represents categorical data. For example, if you want to calculate a linear regression, you need numerical predictors. However, it is very common that categorical variables also make a notable contribution to variance education. Below is shown how to create dummy variables and use them in a regression analysis.
For this post the dataset Gender discrimination from the statistic platform “Kaggle” was used. You can download it from my GitHub Repository.
2 Loading the libraries and the data
import pandas as pd
import numpy as np
import statsmodels.formula.api as smf
import matplotlib.pyplot as pltgender_discrimination = pd.read_csv("path/to/file/gender_discrimination.csv")3 Preparation of the dataframe
show_dummy = gender_discrimination[['Gender', 'Exper', 'Rank', 'Sal95']]
vals_to_replace_gender = {0:'Female', 1:'Male'}
vals_to_replace_rank = {1:'Assistant', 2:'Associate', 3:'Full_Professor'}
show_dummy['Gender'] = show_dummy['Gender'].map(vals_to_replace_gender)
show_dummy['Rank'] = show_dummy['Rank'].map(vals_to_replace_rank)
show_dummy.columns = ['Gender', 'Years_of_Experiences', 'Job', 'Salary']
show_dummy.head()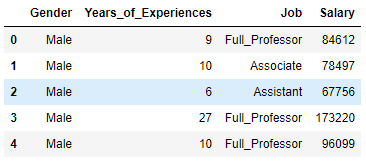
4 How to create dummy variables
dummy_sex = pd.get_dummies(show_dummy['Gender'], prefix="sex")
dummy_sex.head()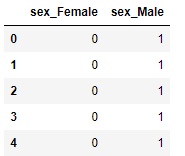
…and add them to the existing datarame.
column_name = show_dummy.columns.values.tolist()
column_name.remove('Gender')
show_dummy = show_dummy[column_name].join(dummy_sex)
show_dummy.head()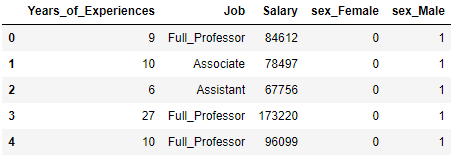
5 Use dummy variables in a regression analysis
In the following it will be examined whether the number of professional years has an influence on the payment.
lin_reg = smf.ols(formula='Salary~Years_of_Experiences', data=show_dummy).fit()
lin_reg.summary()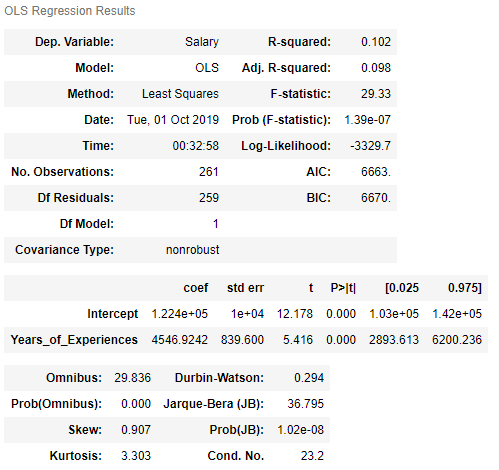
As we can see, we get a R2 of 10,2%.
x = show_dummy['Years_of_Experiences']
y = show_dummy['Salary']
plt.scatter(x, y)
plt.title('Scatter plot: Years_of_Experiences vs. Salary')
plt.xlabel('Years_of_Experiences')
plt.ylabel('Salary')
plt.show()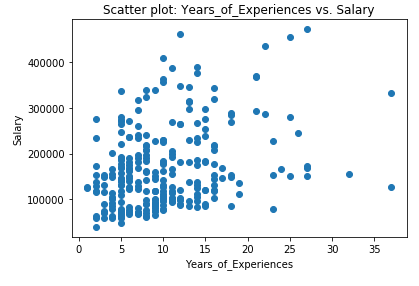
np.corrcoef(x, y)
Now let’s see if the newly created dummy variables (the gender) can improve the result.
lin_reg2 = smf.ols(formula='Salary~Years_of_Experiences+sex_Female+sex_Male', data=show_dummy).fit()
lin_reg2.summary()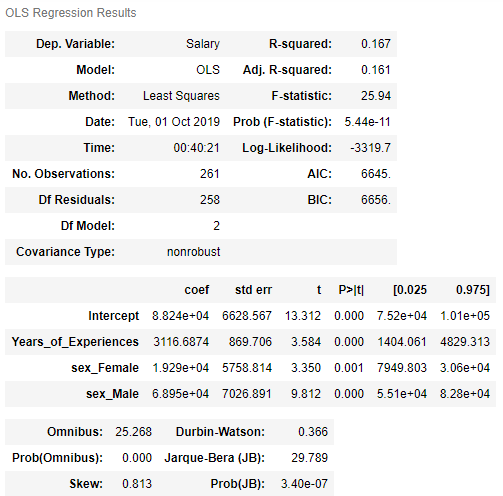
Yes it could. We get a new R2 of 16,7%.
6 Dummy variables with more than two characteristics
Usually, dummy variables have only two characteristics. However, it can happen that they can have more than two. But this is not a problem. Look at the variable Job:
dummy_job = pd.get_dummies(show_dummy['Job'], prefix="Job")
dummy_job.head()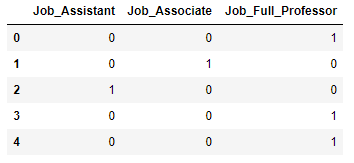
column_name = show_dummy.columns.values.tolist()
column_name.remove('Job')
show_dummy = show_dummy[column_name].join(dummy_job)
show_dummy.head()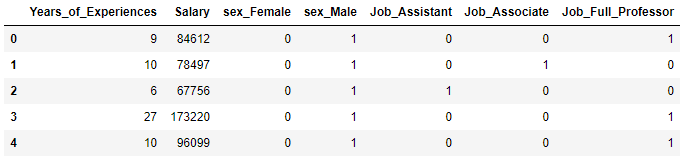
7 How to deal with multiple categorical features in a dataset
To show how to create dummy variables in a data set that contains many categorical variables, we reload the data set ‘gender_discrimination’ and prepare it as shown in step 3 again.
gender_discrimination = pd.read_csv("gender_discrimination.csv")
show_dummy = gender_discrimination[['Gender', 'Exper', 'Rank', 'Sal95']]
vals_to_replace_gender = {0:'Female', 1:'Male'}
vals_to_replace_rank = {1:'Assistant', 2:'Associate', 3:'Full_Professor'}
show_dummy['Gender'] = show_dummy['Gender'].map(vals_to_replace_gender)
show_dummy['Rank'] = show_dummy['Rank'].map(vals_to_replace_rank)
show_dummy.columns = ['Gender', 'Years_of_Experiences', 'Job', 'Salary']
show_dummy.head()
In the first step, we select all categorical variables. Then we create dummy variables for each categorical variable. In the end, we combine all dummy and non-categorical variables and exclude unnecessary columns from the final data set.
#Just select the categorical variables
cat_col = ['object']
cat_columns = list(show_dummy.select_dtypes(include=cat_col).columns)
cat_data = show_dummy[cat_columns]
cat_vars = cat_data.columns
#Create dummy variables for each cat. variable
for var in cat_vars:
cat_list = pd.get_dummies(show_dummy[var], prefix=var)
show_dummy=show_dummy.join(cat_list)
data_vars=show_dummy.columns.values.tolist()
to_keep=[i for i in data_vars if i not in cat_vars]
#Create final dataframe
show_dummy_final=show_dummy[to_keep]
show_dummy_final.columns.values
Voilà !
8 Conclusion
Creating and using dummy variables is essential in machine learning because it can significantly improve results.