1 Introduction
Splitting the dataset in training and testing the dataset is one operation every Data Scientist has to perform befor applying any models. The training dataset is the one on which the model is built and the testing dataset is used to check the accuracy of the model. Generally, the training and testing datasets are split in the ratio of 75:25 or 80:20. There are various ways to split the data into two halves. Here I will show two methods to do this.
For this post the dataset flight from the statistic platform “Kaggle” was used. You can download it from my GitHub Repository.
Loading the libraries and the data
import pandas as pd
import numpy as npflight = pd.read_csv("path/to/file/flight.csv")2 Preparation
For the two methods shown below, the first hundred lines from the record flight are used.
sampling = flight.iloc[0:100,:]
sampling.shape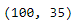
3 Split-Methods
3.1 Customer Churn Model
The division took place here in a ratio of 80:20.
a=np.random.randn(len(sampling))
check=a<0.8
training=sampling[check]
testing=sampling[~check]len(training)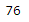
len(testing)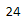
3.2 Train-Test Split via scikit-learn
from sklearn.model_selection import train_test_split
train, test = train_test_split(sampling, test_size = 0.2)len(train)
len(test)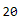
4 Train-Test-Validation Split
Particular in the deep learning area (for example artificial neural networks), it is necessary to hold back part of the data set for validation purposes in addition to the training and test part.We can also do this with the train test split function shown above from scikit-learn. You only have to use this function twice in a row and change the percentage of the division. Let’s see here with the self-generated sample data set:
df = pd.DataFrame(np.random.randint(0,100,size=(10000, 4)), columns=['Var1', 'Var2', 'Var3', 'Target_Var'])
df.head()
df.shape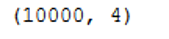
Ok we have generated 4 columns with 10k rows each.
Now we assign the predictors and the criterion to an object. This is a common step to train a machine learning model and could have already done with the previous methods as well.
x = df.drop('Target_Var', axis=1)
y = df['Target_Var']Now we use the train_test_split function twice. First split with 80:20, second with 75:25.
trainX_FULL, testX, trainY_FULL, testY = train_test_split(x, y, test_size = 0.2)trainX, validationX, trainY, validationY = train_test_split(trainX_FULL, trainY_FULL, test_size = 0.25)As a result, we receive a training part of 6,000 observations and a validation and test part of 2,000 observations each:
print(trainX.shape)
print(validationX.shape)
print(testX.shape)
print(trainY.shape)
print(validationY.shape)
print(testY.shape)
5 Conclusion
Now we are ready for predictive modelling.