1 Introduction
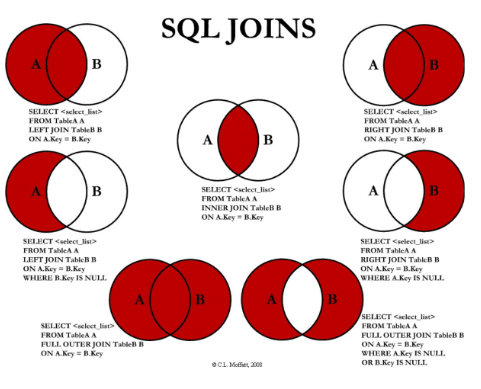
Source: C.L. Moffatt
One of the essential skills of a data scientist is to generate and join data from different sources. For this purpose, I will create four example tables in the following chapter, on which I will subsequently show the different joins.
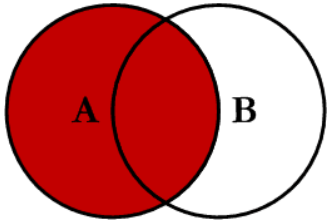
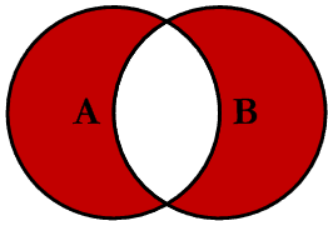
Here I orient myself at the diagram shown above, which shows the usual joins from the SQL area.
These we will imitate in the following in python.
2 Loading the Libraries and the Data
import pandas as pd
import numpy as npCountries_Main = pd.DataFrame({'Country_ID': [1, 2, 3, 4],
'Country_Name': ['Egypt',
'Brazil',
'Germany',
'Malta']})
Countries_Main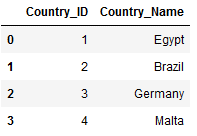
Countries_Capital = pd.DataFrame({'Country_ID': [1, 2, 3, 4],
'Capital_Name': ['Cairo',
'Brasilia',
'Berlin',
'Valletta']})
Countries_Capital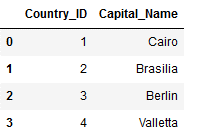
Countries_Inhabitants = pd.DataFrame({'Country_ID': [1, 2, 4],
'Inhabitants': [93.4, 207.9, 0.44]})
Countries_Inhabitants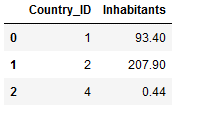
Countries_Land_Area = pd.DataFrame({'Country_ID': [1, 2, 3],
'Land_Area': [1, 8.5, 0.36]})
Countries_Land_Area
Here is another overview of the tables I created:

3 Pandas concat-Function
I use the concat function when I want to concatenate two data sets quick and dirty. The connection of the records can be done either along the rows or the columns (the records must have the same length). But you have to be careful, because the connection along the columns is taken over 1:1 and has no logic behind it.
If I want to connect tables with a certain logic, I use the merge function (described in more detail in the following chapter 4).
As said a quick and dirty solution.
3.1 Concat along rows
Customer_1 = pd.DataFrame({'ID': [1, 2],
'Name': ['Marc', 'Sven']})
Customer_2 = pd.DataFrame({'ID': [98, 99],
'Name': ['Sarah', 'Jenny']})
print(Customer_1)
print()
print(Customer_2)
df_final_concat_rows = pd.concat([Customer_1, Customer_2])
df_final_concat_rows
print()
print('Countries_Main:')
print()
print(Countries_Main)
print('--------------------------')
print()
print('Countries_Capital:')
print()
print(Countries_Capital)
print('--------------------------')
df_final_concat_rows2 = pd.concat([Countries_Main, Countries_Capital])
df_final_concat_rows2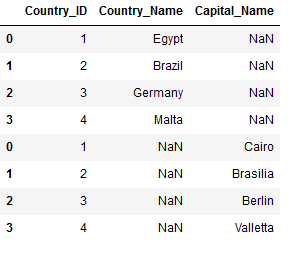
3.2 Concat along columns
print()
print('Countries_Main:')
print()
print(Countries_Main)
print('--------------------------')
print()
print('Countries_Capital:')
print()
print(Countries_Capital)
print('--------------------------')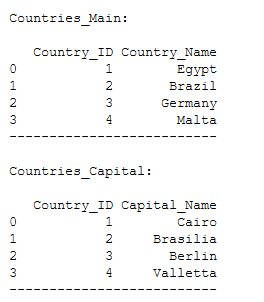
df_final_concat = pd.concat([Countries_Main, Countries_Capital], axis=1)
df_final_concat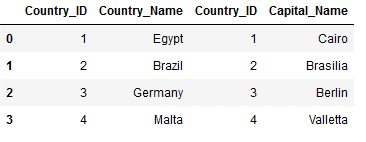
4 Types of Joins
Now we come to joins for tables, which are subject to a certain logic.
Below I will walk through the different types of joins and explain how they work using the sample tables I have created. Furthermore I will always show at the beginning, with which tables exactly I will execute the following join.
4.1 Inner Join
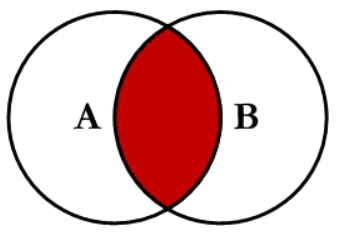
Source: C.L. Moffatt
print()
print('Countries_Inhabitants:')
print()
print(Countries_Inhabitants)
print('--------------------------')
print()
print('Countries_Land_Area:')
print()
print(Countries_Land_Area)
This join will return all of the records in the left table (Countries_Inhabitants) that have a matching record in the right table (Countries_Land_Area).
df_final_inner = pd.merge(Countries_Inhabitants,
Countries_Land_Area,
on='Country_ID', how='inner')
df_final_inner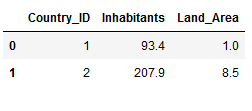
4.2 Left Join
Source: C.L. Moffatt
print()
print('Countries_Main:')
print()
print(Countries_Main)
print('--------------------------')
print()
print('Countries_Capital:')
print()
print(Countries_Capital)
print('--------------------------')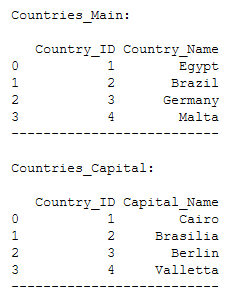
This join will return all of the records in the left table (Countries_Main) regardless if any of those records have a match in the right table (Countries_Capital ).
df_final_left = pd.merge(Countries_Main,
Countries_Capital,
on='Country_ID',
how='left')
df_final_left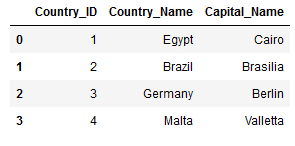
4.2.1 left_on & right_on
If the columns on the basis of which the join is to be executed are named differently in the two data sets, you can use the parameters left_on and right_on.
Countries_Additional = pd.DataFrame({'ID_of_Country': [1, 2, 3, 4],
'Additional_Info': ['Add_Info', 'Add_Info', 'Add_Info', 'Add_Info']})
print()
print('Countries_Main:')
print()
print(Countries_Main)
print('--------------------------')
print()
print('Countries_Additional:')
print()
print(Countries_Additional)
print('--------------------------')
df_final_left2 = pd.merge(Countries_Main,
Countries_Additional,
left_on='Country_ID',
right_on='ID_of_Country',
how='left')
#Removes unnecessary columns
df_final_left2 = df_final_left2.drop('ID_of_Country', axis=1)
df_final_left2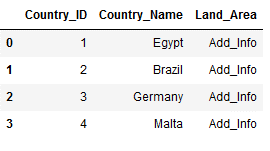
4.2.2 Missing Keys
But what happens if a value we want to join to is not available in the second (right) table? Look here:
print()
print('Countries_Main:')
print()
print(Countries_Main)
print('--------------------------')
print()
print('Countries_Inhabitants:')
print()
print(Countries_Inhabitants)
print('--------------------------')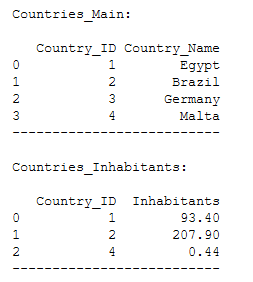
df_final_left3 = pd.merge(Countries_Main,
Countries_Inhabitants,
on='Country_ID',
how='left')
df_final_left3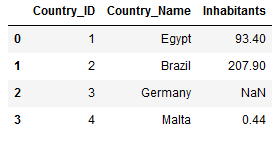
The missing information is replaced with a NULL value.
4.3 Right Join
Source: C.L. Moffatt
print()
print('Countries_Main:')
print()
print(Countries_Main)
print('--------------------------')
print()
print('Countries_Inhabitants:')
print()
print(Countries_Inhabitants)
print('--------------------------')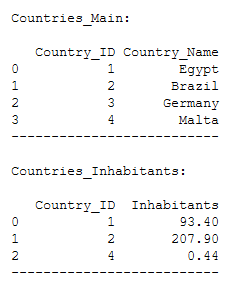
This join will return all of the records in the right table (Countries_Inhabitants) regardless if any of those records have a match in the left table (Countries_Main).
df_final_right = pd.merge(Countries_Main,
Countries_Inhabitants,
on='Country_ID',
how='right')
df_final_right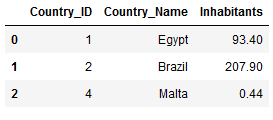
4.4 Outer Join
Source: C.L. Moffatt
As known as FULL OUTER JOIN or FULL JOIN.
print()
print('Countries_Inhabitants:')
print()
print(Countries_Inhabitants)
print('--------------------------')
print()
print('Countries_Land_Area:')
print()
print(Countries_Land_Area)
print('--------------------------')
This join will return all of the records from both tables, joining records from the left table (Countries_Inhabitants) that match records from the right table (Countries_Land_Area).
df_final_outer = pd.merge(Countries_Inhabitants,
Countries_Land_Area,
on='Country_ID',
how='outer')
df_final_outer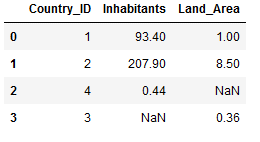
Here again the output of the Inner JOIN for comparison:
4.5 Left Excluding Join
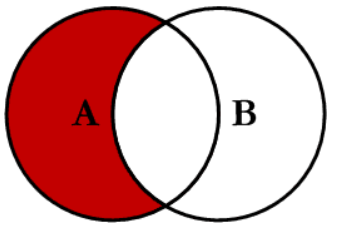
Source: C.L. Moffatt
print()
print('Countries_Inhabitants:')
print()
print(Countries_Inhabitants)
print('--------------------------')
print()
print('Countries_Land_Area:')
print()
print(Countries_Land_Area)
print('--------------------------')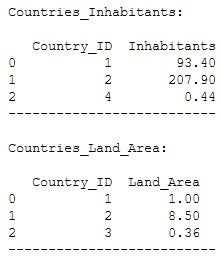
This join will return all of the records in the left table (Countries_Inhabitants) that do not match any records in the right table (Countries_Land_Area).
df_final_left_excl = pd.merge(Countries_Inhabitants,
Countries_Land_Area,
on='Country_ID',
indicator=True,
how='left').query('_merge=="left_only"')
#Removes unnecessary columns
df_final_left_excl = df_final_left_excl.drop('_merge', axis=1)
df_final_left_excl
4.6 Right Excluding Join
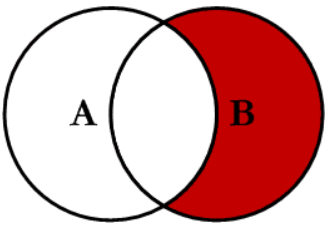
Source: C.L. Moffatt
print()
print('Countries_Inhabitants:')
print()
print(Countries_Inhabitants)
print('--------------------------')
print()
print('Countries_Land_Area:')
print()
print(Countries_Land_Area)
print('--------------------------')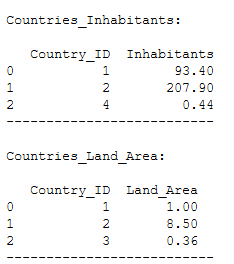
This join will return all of the records in the right table (Countries_Land_Area) that do not match any records in the left table (Countries_Inhabitants).
df_final_right_excl = pd.merge(Countries_Inhabitants,
Countries_Land_Area,
on='Country_ID',
indicator=True,
how='right').query('_merge=="right_only"')
#Removes unnecessary columns
df_final_right_excl = df_final_right_excl.drop('_merge', axis=1)
df_final_right_excl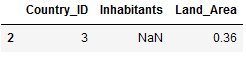
4.7 Outer Excluding Join
Source: C.L. Moffatt
print()
print('Countries_Inhabitants:')
print()
print(Countries_Inhabitants)
print('--------------------------')
print()
print('Countries_Land_Area:')
print()
print(Countries_Land_Area)
print('--------------------------')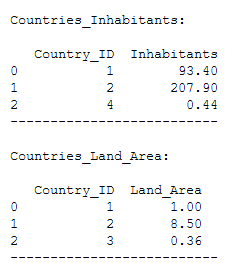
This join will return all of the records in the left table (Countries_Inhabitants) and all of the records in the right table (Countries_Land_Area) that do not match.
df_final_outer_excl = pd.merge(Countries_Inhabitants,
Countries_Land_Area,
on='Country_ID',
indicator=True,
how='outer').query('_merge!="both"')
#Removes unnecessary columns
df_final_outer_excl = df_final_outer_excl.drop('_merge', axis=1)
df_final_outer_excl
Here again for comparison the result of the Outer JOIN / Full Outer JOIN:
4.8 Warning
Here I show exactly what I mean by that:
warning_df_1 = pd.DataFrame({'Country_ID': [1, 2, 3, np.NaN],
'Country_Name': ['Egypt',
'Brazil',
'Germany',
'Malta']})
warning_df_2 = pd.DataFrame({'Country_ID': [1, 2, np.NaN, 4],
'Capital_Name': ['Cairo',
'Brasilia',
'Berlin',
'Valletta']})
print()
print('warning_df_1:')
print()
print(warning_df_1)
print('--------------------------')
print()
print('warning_df_2:')
print()
print(warning_df_1)
print('--------------------------')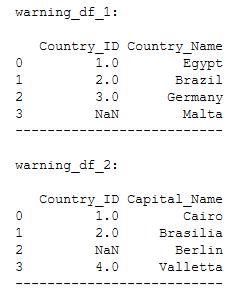
warning_df_final = pd.merge(warning_df_1,
warning_df_2,
on='Country_ID',
how='left')
warning_df_final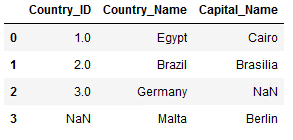
Here again for comparison the result of the Left JOIN:
5 Merge multiple data frames
Of course, you also have the possibility to execute several joins (here left join) simultaneously / nested.
5.1 Merge 3 DFs at once
print()
print('Countries_Main:')
print()
print(Countries_Main)
print('--------------------------')
print()
print('Countries_Capital:')
print()
print(Countries_Capital)
print('--------------------------')
print()
print('Countries_Inhabitants:')
print()
print(Countries_Inhabitants)
print('--------------------------')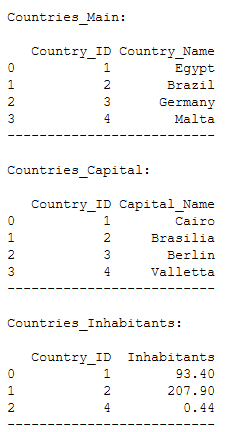
multiple_merge = pd.merge(pd.merge(Countries_Main,
Countries_Capital,
on='Country_ID',
how='left'),
Countries_Inhabitants,
on='Country_ID',
how='left')
multiple_merge.head()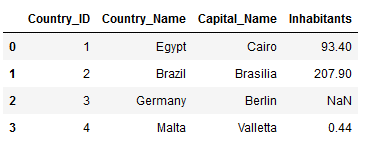
5.2 Merge 4 DFs at once
print()
print('Countries_Main:')
print()
print(Countries_Main)
print('--------------------------')
print()
print('Countries_Capital:')
print()
print(Countries_Capital)
print('--------------------------')
print()
print('Countries_Inhabitants:')
print()
print(Countries_Inhabitants)
print('--------------------------')
print()
print('Countries_Land_Area:')
print()
print(Countries_Land_Area)
print('--------------------------')
multiple_merge2 = pd.merge(pd.merge(pd.merge(Countries_Main,
Countries_Capital,
on='Country_ID',
how='left'),
Countries_Inhabitants,
on='Country_ID',
how='left'),
Countries_Land_Area,
on='Country_ID',
how='left')
multiple_merge2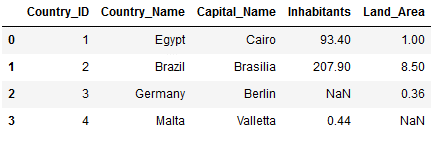
6 Conclusion
In this post I have shown examples of how to use the most common join types. If you want to know what the SQL syntax is for this, check out this post of mine: SQL Joins