1 Introduction
Anyone who has ever worked with R probably knows the very useful pipe operator %>%. Python also has a similar one that will be presented in different versions below.
For this post the dataset flight from the statistic platform “Kaggle” was used. You can download it from my GitHub Repository.
Loading the libraries and the data
import pandas as pdflight = pd.read_csv("path/to/file/flight.csv")2 Python’s Pipe - Operator like R’s %>%
df = (
flight
[['DayOfWeek', 'UniqueCarrier', 'Origin_Airport']]
)
df.head()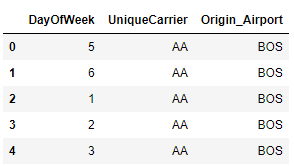
2.1 Filter and select
df = (
flight
[flight.DayOfWeek > 3]
[['DayOfWeek', 'UniqueCarrier', 'Origin_Airport']]
)
df.head()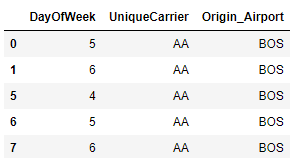
2.2 Multiple filter and select
df = (
flight
[(flight.DayOfWeek > 3) & (flight.Origin_Airport == 'JFK')]
[['DayOfWeek', 'UniqueCarrier', 'Origin_Airport']]
)
df.head()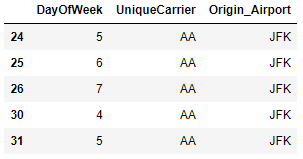
2.3 Sample and sort
(
flight
.sample(n=3)
.sort_values('DayOfWeek')
[['DayOfWeek', 'UniqueCarrier', 'Origin_Airport']]
)
2.4 Multiple group by and summarize
df = (
flight
.groupby(['Origin_Airport', 'DayOfWeek'])
.agg({'Scheduled_Departure': 'mean'})
# agg = summarize
.rename(columns={"Scheduled_Departure": "avg_Scheduled_Departure"})
# due to agg we have to rename
.reset_index()
# agg returns a MultiIndex therefore reset_index()
.round({'avg_Scheduled_Departure': 2})
)
df.head(12)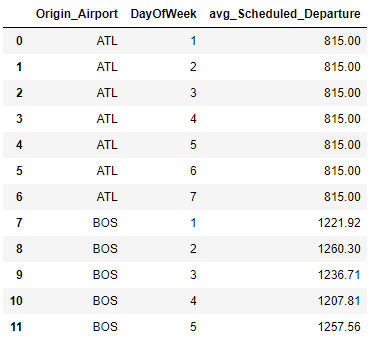
2.5 Group by and multiple summarize
df = (
flight
.groupby(['Origin_Airport'])
.agg({'Scheduled_Departure': 'mean',
'Dep_Delay': 'mean',
'Scheduled_Arrival': 'mean',
'Arrival_Delay': 'mean'})
.rename(columns={"Scheduled_Departure": "avg_Scheduled_Departure",
"Dep_Delay": "avg_Dep_Delay",
"Scheduled_Arrival": "avg_Scheduled_Arriva",
"Arrival_Delay": "avg_Arrival_Delay"})
.reset_index()
.round({'avg_Scheduled_Departure': 2,
'avg_Dep_Delay': 2,
'avg_Scheduled_Arriva': 2,
'avg_Arrival_Delay':2})
)
df.head(12)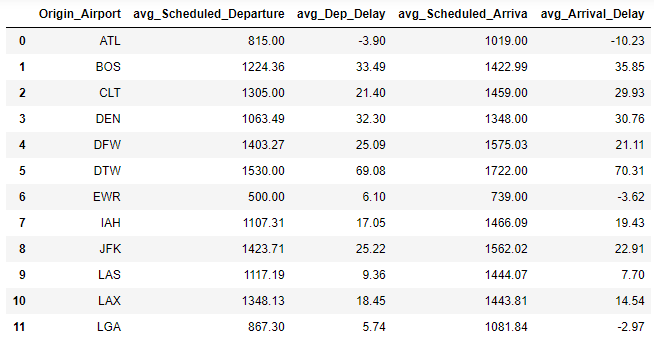
3 Conclusion
In my opinion, the Pipe Operator is a very useful feature which can be used in a variety of ways.