1 Introduction
In some situations it is necessary to select all columns of a certain data type. For example if you want to convert all categorical variables into dummy variables in order to be able to calculate a regression.
For this post the dataset Bank Data from the platform “UCI Machine Learning repository” was used. You can download it from my GitHub Repository.
2 Loading the libraries and the data
import numpy as np
import pandas as pdbank = pd.read_csv("path/to/file/bank.csv", sep=";")
bank.dtypes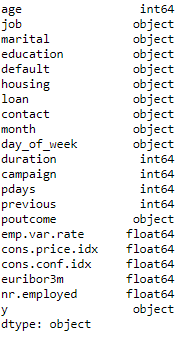
bank.shape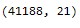
3 Selection of numeric variables
Only numerical variables will be considered here:
num_col = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
numerical_columns = list(bank.select_dtypes(include=num_col).columns)
bank_numeric = bank[numerical_columns]bank_numeric.shape
bank_numeric.dtypes
4 Selection of categorical variables
Only categorical variables will be considered here:
obj_col = ['object']
object_columns = list(bank.select_dtypes(include=obj_col).columns)
bank_categorical = bank[object_columns]bank_categorical.shape
bank_categorical.dtypes
5 Conclusion
This publication showed how to selectively select numeric or categorical variables.