1 Introduction
One funcion you always need to work with data is to import the records you want to analyze. This publication will show how to load data from different data types for further processing or analysis. The standard library pandas offers a wide range of possibilities.
For this post the dataset twitter from the statistic platform “Kaggle” was used as well as a self-created record as a text format called some_TEXT_data_as_JSON. You can download them from my GitHub Repository.
2 Loading the libraries
import pandas as pd
import json
import datetime3 Reading Files
3.1 Reading csv-files
3.1.1 From a Local Source
Probably the most used file format is the csv-file. We can simply load csv files with the following syntax:
df = pd.read_csv("df.csv")Please note that an appropriate path to the location of the file (see example below) is given if necessary.
df = pd.read_csv("path/to/file/df.csv")Most of the csv files should be easy to read in this way. However, there are always situations in which the csv file is stored with, for example, another delimiter. By default this “,” within the pd.read_csv function. To change this we have to add the ‘sep’ argument:
df = pd.read_csv("df.csv", sep=";")There are a couple of other ways to read csv files with pandas read_csv-function:
- Read csv file without header row
- Skip rows but keep header
- Read data and specify missing values or set an index column
- Read csv File from External URL
- Skip Last 5 Rows While Importing csv
- Read only first 5 or more rows
- Read only specific columns or rows
- Change column type while importing csv
…
For a detailed description have a look at this pandas read_csv documentation “here”
3.1.2 From GitHub directly
However, with csv files you have the option to load them directly from GitHub.
To do this, click on the corresponding file in GitHub and select Raw (see screenshot below).
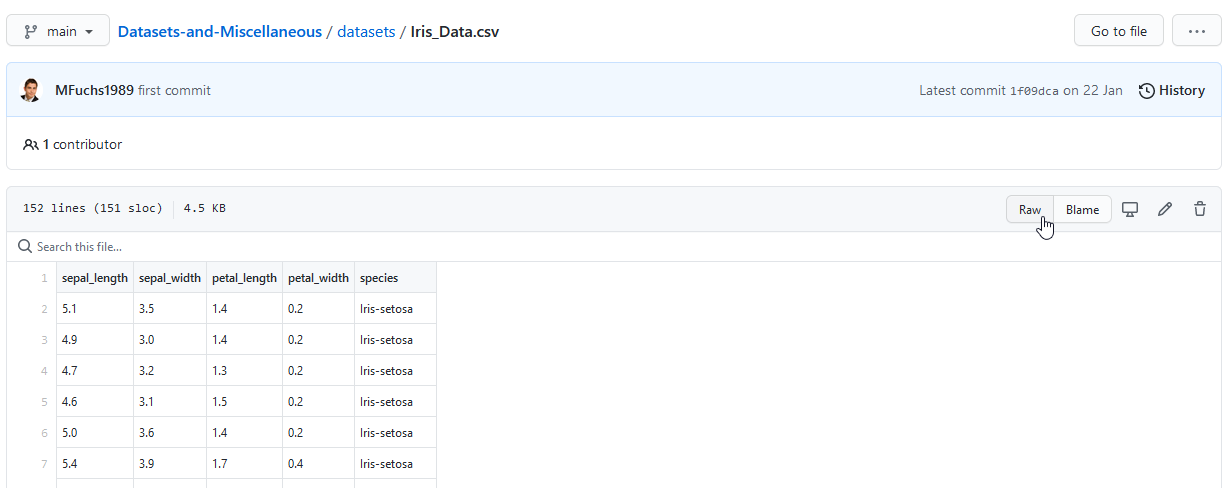
The address can then be copied and pasted into the code below.
url = "https://raw.githubusercontent.com/MFuchs1989/Datasets-and-Miscellaneous/main/datasets/Iris_Data.csv"
df_iris = pd.read_csv(url, error_bad_lines=False)
df_iris.head()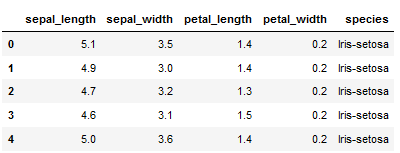
3.2 Reading json files
Another very popular format is json. This usually looks like this:
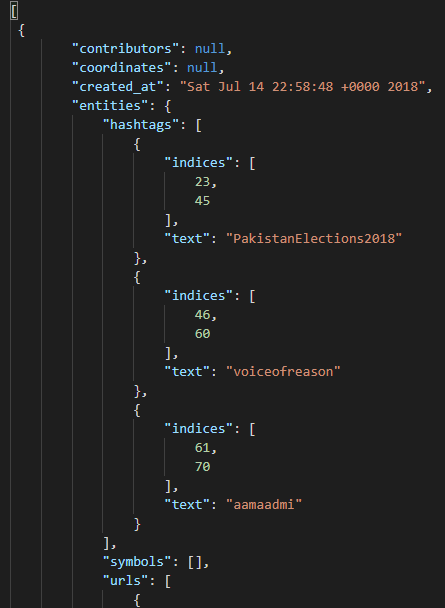
Also for this pandas offers a quite simple possibility. To illustrate this example, we use a kaggle record of data from twitter.
df = pd.read_json("twitter.json")
df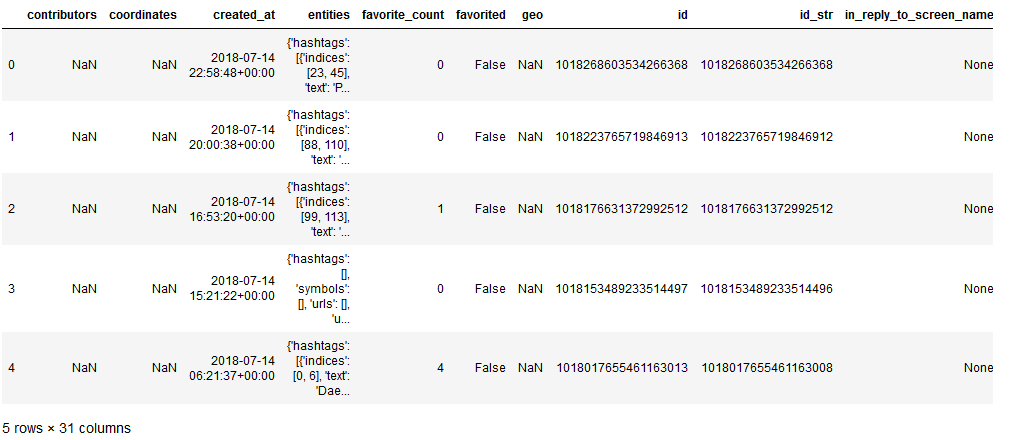
3.3 Read text files
From time to time it also happens that files are made available to you as text files as the below picture shows.
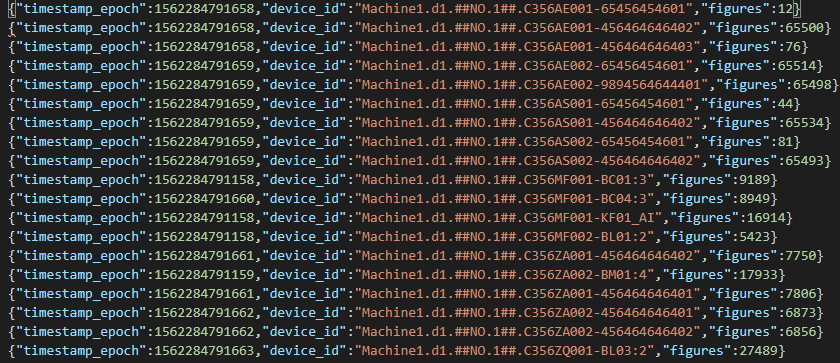
Looks a bit tricky at first (especially since this file was named as json format but really is not a real json). But this doesn’t matter. We can read this file in two ways.
3.3.1 with a for loop
Here you have to know which column names are contained in the file.
f = open("some_TEXT_data_as_JSON.json", "r")
firstLine = 1
for x in f:
y = json.loads(x)
if firstLine == 1:
df = pd.DataFrame([[y['timestamp_epoch'], y['device_id'], y['figures']]], columns=['timestamp_epoch', 'device_id', 'figures'])
firstLine = 0
continue
df2 = pd.DataFrame([[y['timestamp_epoch'], y['device_id'], y['figures']]], columns=['timestamp_epoch', 'device_id', 'figures'])
frames = [df, df2]
df = pd.concat(frames,ignore_index=True, sort=False)
df.head()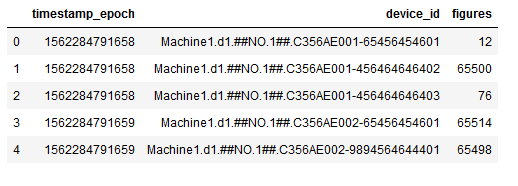
This method is a good approach for smaller data sets. If the data set is too large, the processing time could increase dramatically.
3.3.2 with read_csv
Alternatively you can use the read_csv function. In this case, you have to note that you still give the other file format (here json).
df = pd.read_csv('some_TEXT_data_as_JSON.json', sep=":", header=None)
df.columns = ['to_delete', 'timestamp_epoch', 'device_id', 'figures']
df.drop(["to_delete"], axis = 1, inplace = True)
df.timestamp_epoch = df.timestamp_epoch.map(lambda x: x.split(',')[0])
df.device_id = df.device_id.map(lambda x: x.split(',')[0])
df.figures = df.figures.map(lambda x: x.split('}')[0])
df.head()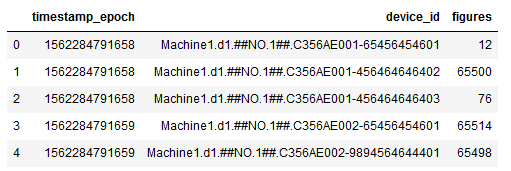
Hereby I used the map function in combination with lambda function to bring the data in the correct shape. How map works and can be used exactly see in this publication “publication (String Manipulation. An intuition.)” of mine
3.3.2.1 Convert epoch time to DateTime
As you may have noticed, the column timestamp_epoch contains an epoch notation, which is not necessarily readable for everyone. Therefore, it is worth to reshape them accordingly.
df['timestamp_epoch2'] = df.timestamp_epoch.astype(float)
df['new_timestamp_epoch'] = df.timestamp_epoch2 / 1000
df['new_timestamp_epoch_round'] = df.new_timestamp_epoch.round()
df['new_timestamp_epoch_round'] = df.new_timestamp_epoch_round.astype(int)
df['final'] = df.new_timestamp_epoch_round.map(lambda x: datetime.datetime.utcfromtimestamp(x).strftime('%Y-%m-%d %H:%M:%S'))
df['DateTime'] = pd.to_datetime(df['final'])
df.drop(["timestamp_epoch2", "new_timestamp_epoch", "new_timestamp_epoch_round", "final"], axis = 1, inplace = True)
df.head()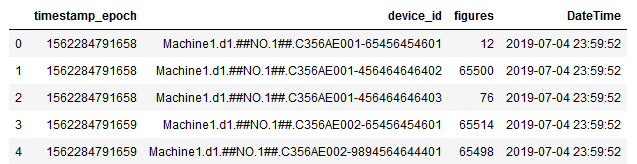
Voilà !
4 Writing files
4.1 Write to csv
At this point, the question arises how the newly prepared data record can be easily stored. Almost every “read_from” has a “write_to” command. Let’s do so with our previously created dataframe:
df.to_csv('NewDataFrame.csv')If you do not want to save the index as a new separate column, you can use the following addition:
df.to_csv('NewDataFrame.csv', index = False)This data set is now saved to the previously set path or any one that can be integrated in this command.
4.2 Write to excel
The CSV format is the most common format in which data is saved, but it is still necessary / desired to save the data in Excel from time to time.
To do so I use the .to_excel function in combination with the xlsxwriter-engine. This is pretty much the same simple process as saving in a csv format. Therefore, this time we not only do the normal storage of the file but also assign it a special label.
Imagine our task is to create a report on financial data on a regular basis and to save it accordingly in excel after the date of creation and the respective quarter.
We do not want to name each time by hand. So we let python work for us.
Here is our new dataframe with financial data:
df = pd.DataFrame({'Transaction': ['46568454684', '89844548864', '90487651685'],
'Amount': [32,22,6200,],
'Currancy': ['EUR', 'CHF', 'THB']})
df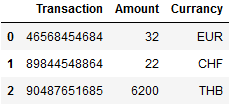
Well, in order to supplement the naming of the file with information at the current point in time, we have to have the current values displayed.
now = datetime.datetime.now()
now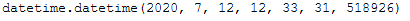
Here we can also have individual elements output. For example year and month:
now.year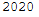
now.month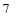
To get the current quarter, I wrote the following function:
def get_quarter(month):
if (month <= 3):
return 'Q1'
elif (month <= 6) and (month > 3):
return 'Q2'
elif (month <= 9) and (month > 6):
return 'Q3'
elif (month <= 12) and (month > 9):
return 'Q4' Let’s test the created function:
for i in range(1, 13):
total = get_quarter(i)
print(total)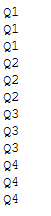
Works fine!
Now we save the information that we want to use in the naming of the file in our own objects.
now_year = now.year
now_year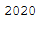
month = now.month
now_quarter = get_quarter(month)
now_quarter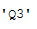
Then we combine the two objects:
year_quarter = str(now_year) + now_quarter
year_quarter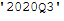
Last but not least the current date:
now_date = now.strftime("%Y-%m-%d")
now_date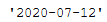
Now we save our data record in Excel and give this file our desired name with the automatically generated information at the time.
df.to_excel(year_quater + '_Financial_Data_'+ now_date + '.xlsx', sheet_name='Sheet1', engine='xlsxwriter')The result looks like this:

Or you simply assign a name of your choice:
df.to_excel('My_DataFrame.xlsx', sheet_name='Sheet1', engine='xlsxwriter')4.2.1 Writing multiple DFs to one Excel File
If you have now created several dataframes and want to write them into a common Excel file (into separate sheets), you can proceed as follows:
writer = pd.ExcelWriter('Name_of_Excel_File.xlsx', engine='xlsxwriter')
df1.to_excel(writer, sheet_name='Sheet1')
df2.to_excel(writer, sheet_name='Sheet2')
df3.to_excel(writer, sheet_name='Sheet3')
writer.save()5 How to read further data types
In addition to csv and json, there are many other file formats that can also be read in python with the pandas read_ * command. Here is a list of them:
- Excel (pd.read_excel())
- HTML (pd.read_html())
- Feather (pd.read_feather())
- Parquet (pd.read_parquet())
- SAS (pd.read_sas())
- SQL (pd.read_sql())
- Google BigQuery (pd.gbq())
- STATA (pd.read_stata())
- Clipboard (pd.read_clipboard())
6 Conclusion
In this post various ways and possibilities were shown to read different data formats in python.